| Oracle7 Server Concepts Manual | Library |
Product |
Contents |
Index |
| Oracle7 Server Concepts Manual | Library |
Product |
Contents |
Index |
![]()
![]()
Shakespeare: Hamlet
This chapter discusses the memory structures and processes in an Oracle database system. It includes:
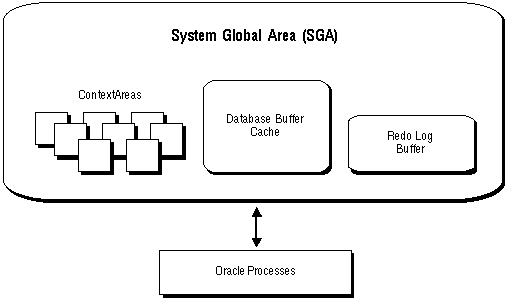
Figure 9 - 1. An Oracle Instance
The remaining sections of this chapter explain the memory and process structures and configurations associated with an Oracle instance. See Oracle7 Parallel Server Concepts & Administration for more information about the Oracle Parallel Server. See the Trusted Oracle7 Server Administrator's Guide for more information about Trusted Oracle.
The process structure of Oracle is important because it defines how multiple activities can occur and how they are accomplished. For example, two goals of a process structure might be
Figure 9 - 2 shows a single-process Oracle instance. The single process executes all code associated with the database application and Oracle.
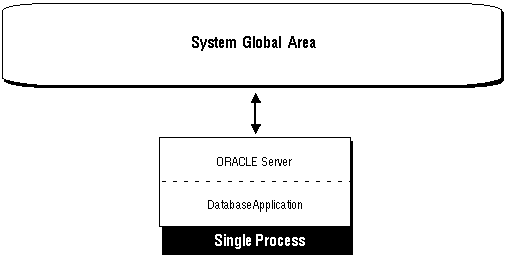
Figure 9 - 2. A Single-Process Oracle Instance
Only one user can access an Oracle instance in a single-process environment; multiple users cannot access the database concurrently. For example, Oracle running under the MS-DOS operating system on a PC can only be accessed by a single user because MS-DOS is not capable of running multiple processes.
Figure 9 - 3 illustrates a multiple-process Oracle instance. Each connected user has a separate user process and several background processes are used to execute Oracle. This figure might represent multiple concurrent users running an application on the same machine as Oracle; this particular configuration is usually on a mainframe or minicomputer.
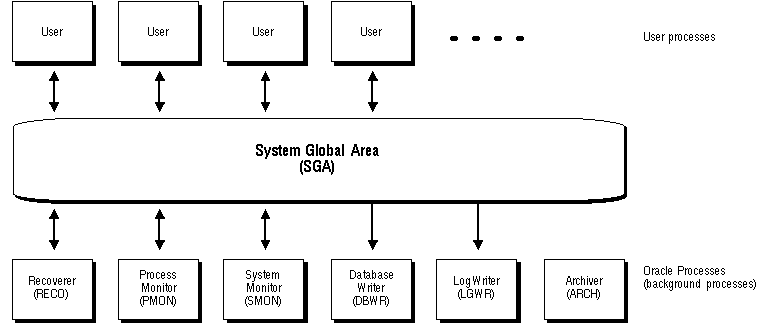
Figure 9 - 3. A Multiple-Process Oracle Instance
In a multiple-process system, processes can be categorized into two groups: user processes and Oracle processes. The following sections explain these classes of processes.
Oracle creates server processes to handle the requests of user processes connected to the instance. Often, when the application and Oracle operate on the same machine rather than over a network, a user process and its corresponding server process are combined into a single process to reduce system overhead. However, when the application and Oracle operate on different machines, a user process communicates with Oracle via a separate server process. See "Variations in Oracle Configuration" ![[*]](jump.gif) for more information.
for more information.
Server processes (or the server portion of combined user/server processes) created on behalf of each user's application may perform one or more of the following:
Additional Information: On many operating systems, background processes are created automatically when an instance is started. On other operating systems, the server processes are created as a part of the Oracle installation. See your Oracle operating system-specific documentation for details on how these processes are created.
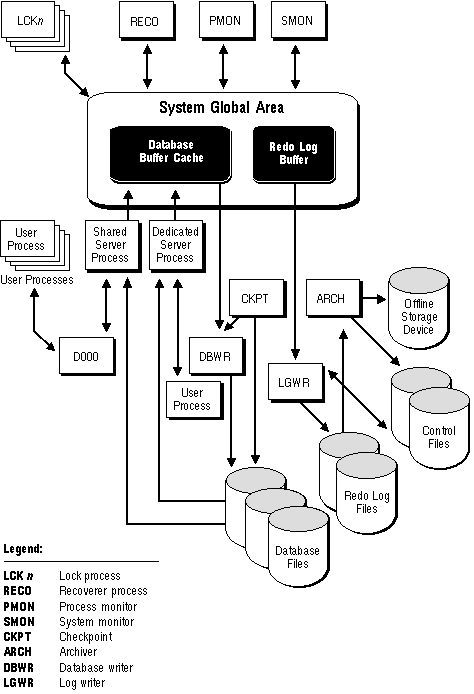
Figure 9 - 4. The Background Processes of a Multiple-Process Oracle Instance
Database Writer (DBWR) Database Writer process (DBWR) writes buffers to datafiles. DBWR is an Oracle background process responsible for buffer cache management. For more information about the database buffer cache, see "The Database Buffer Cache" .
When a buffer in the buffer cache is modified, it is marked "dirty". The primary job of the DBWR process is to keep the buffer cache "clean" by writing dirty buffers to disk. As buffers are filled and dirtied by user processes, the number of free buffers diminishes. If the number of free buffers drops too low, user processes that must read blocks from disk into the cache are not able to find free buffers. DBWR manages the buffer cache so that user processes can always find free buffers.
An LRU (least recently used) algorithm keeps the most recently used data blocks in memory and thus minimizes I/O. The database writer process (DBWR) keeps blocks that are used often, for example, blocks that are part of frequently accessed small tables or indexes, in the cache so that they do not need to be read in again from disk. To make room in the buffer cache for other blocks, DBWR removes blocks that are accessed infrequently (for example, blocks that are part of very large tables or leaf blocks from very large indexes) from the system global area (SGA). For information about leaf blocks, see "The Internal Structure of Indexes" .
The LRU scheme causes more frequently accessed blocks to stay in the buffer cache so that when a buffer is written to disk, it is unlikely to contain data that may be useful soon. However, if the DBWR process becomes too active, it may write blocks to disk that are about to be needed again.
The buffer cache has multiple LRU latches. Latches are automatic internal locks that protect shared data structures. The initialization parameter DB_BLOCK_LRU_LATCHES controls how many latches are configured and by default is set to the number of CPUs on your system. This is usually a good value to reduce latch contention for the DBWR processes, thus improving performance.
The DBWR process writes dirty buffers to disk under the following conditions:
A time-out occurs if DBWR is inactive for three seconds. In this case, DBWR searches a specified number of buffers on the LRU list and writes any dirty buffers that it finds to disk. Whenever a time-out occurs, DBWR searches a new set of buffers. If the database is idle, DBWR eventually writes the entire buffer cache to disk.
When a checkpoint occurs, the Log Writer process (LGWR) specifies a list of modified buffers that must be written to disk. DBWR writes the specified buffers to disk. For more information about checkpoints, see "Checkpoints" .
Additional Information: On some platforms, an instance can have multiple DBWRs. In such a case, if one DBWR blocks during a write to one disk, the others can continue writing to other disks. The parameter DB_WRITERS controls the number of DBWR processes. See your Oracle operating system-specific documentation for information about DBWR on your platform.
For more information about DBWR and how to monitor and tune the performance of DBWR, see the Oracle7 Server Administrator's Guide and Oracle7 Server Tuning.
Log Writer (LGWR) The Log Writer process (LGWR) writes the redo log buffer to a redo log file on disk. LGWR is an Oracle background process responsible for redo log buffer management. LGWR writes all redo entries that have been copied into the buffer since the last time it wrote. LGWR writes one contiguous portion of the buffer to disk. LGWR writes
for more information about mirrored online redo logs and how LGWR functions in this configuration.
The redo log buffer (see "The Redo Log Buffer" ) is a circular buffer; when LGWR writes redo entries from the redo log buffer to a redo log file, server processes can then copy new entries over the entries in the redo log buffer that have been written to disk. LGWR normally writes fast enough to ensure that space is always available in the buffer for new entries, even when access to the redo log is heavy.
Note: Sometimes, if more buffer space is needed, LGWR writes redo log entries before a transaction is committed. These entries become permanent only if the transaction is later committed.
Oracle uses a "fast commit" mechanism; when a user issues a COMMIT statement, LGWR puts a commit record immediately in the redo log buffer, but the corresponding data buffer changes are deferred until it is more efficient to write them to the datafiles. The atomic write of the redo entry containing the commit record for a transaction is the single event that determines the transaction has committed (then Oracle returns a success code to the committing transaction).
When a user commits a transaction, the transaction is assigned a system change number (SCN), which Oracle records along with the transaction's redo entries in the redo log. SCNs are recorded in the redo log so that recovery operations can be synchronized in Parallel Server configurations and distributed databases. See Oracle7 Parallel Server Concepts & Administration and the Oracle7 Server Administrator's Guide for more information about SCNs and how they are used.
In times of high activity, LGWR may write to the online redo log file using group commits. For example, assume that a user commits a transaction -- LGWR must write the transaction's redo entries to disk. As this happens, other users issue a COMMIT statement. However, LGWR cannot write to the online redo log file to commit these transactions until it has completed its previous write operation. After the first transaction's entries are written to the online redo log file, the entire list of redo entries of waiting transactions (not yet committed) can be written to disk in one operation, requiring less I/O than would transaction entries handled individually. Therefore, Oracle minimizes disk I/O and maximizes performance of LGWR. If requests to commit continue at a high rate, then every write (by LGWR) from the redo log buffer may contain multiple commit records, averaging less than one write per COMMIT.
If the CKPT background process is not present, LGWR is also responsible for recording checkpoints as they occur in every datafile's header. See "Checkpoint (CKPT)" below for more information about this background process.
Checkpoint (CKPT) When a checkpoint occurs, Oracle must update the headers of all datafiles to indicate the checkpoint. In normal situations, this job is performed by LGWR. However, if checkpoints significantly degrade system performance (usually, when there are many datafiles), you can enable the Checkpoint process (CKPT) to separate the work of performing a checkpoint from other work performed by LGWR, the Log Writer process (LGWR).
For most applications, the CKPT process is not necessary. If your database has many datafiles and the performance of the LGWR process is reduced significantly during checkpoints, you may want to enable the CKPT process.
The CKPT process does not write blocks to disk; DBWR always performs that work. The statistic DBWR checkpoints displayed by the System_Statistics monitor in Server Manager indicates the number of checkpoint messages completed, regardless of whether the CKPT process is enabled or not. See the Oracle7 Server Administrator's Guide for information about the effects of changing the checkpoint interval.
Note: See Oracle7 Parallel Server Concepts & Administration for additional information about CKPT in an Oracle Parallel Sever.
System Monitor (SMON) The System Monitor process (SMON) performs instance recovery at instance start up. SMON is also responsible for cleaning up temporary segments that are no longer in use; it also coalesces contiguous free extents to make larger blocks of free space available. In a Parallel Server environment, SMON performs instance recovery for a failed CPU or instance; see Oracle7 Parallel Server Concepts & Administration for more information about SMON in an Oracle Parallel Server.
SMON "wakes up" regularly to check whether it is needed. Other processes can call SMON if they detect a need for SMON to wake up.
Process Monitor (PMON) The Process Monitor (PMON) performs process recovery when a user process fails. PMON is responsible for cleaning up the cache and freeing resources that the process was using. For example, it resets the status of the active transaction table, releases locks, and removes the process ID from the list of active processes.
PMON also periodically checks the status of dispatcher and server processes, and restarts any that have died (but not any that Oracle has killed intentionally).
Like SMON, PMON "wakes up" regularly to check whether it is needed, and can be called if another process detects the need for it.
Recoverer (RECO) The Recoverer process (RECO) is a process used with the distributed option that automatically resolves failures involving distributed transactions. The RECO background process of a node automatically connects to other databases involved in an in-doubt distributed transaction. When the RECO process re-establishes a connection between involved database servers, it automatically resolves all in-doubt transactions.
The RECO process automatically removes rows corresponding to any resolved in-doubt transactions from each database's pending transaction table.
If the RECO background process attempts to establish communication with a remote server, and the remote server is not available or the network connection has not been re-established, RECO automatically tries to connect again after a timed interval. However, RECO waits an increasing amount of time (growing exponentially) before it attempts another connection.
For more information about distributed transaction recovery, see Oracle7 Server Distributed Systems, Volume I.
The RECO background process of an instance is only present if the system permits distributed transactions and if the DISTRIBUTED_TRANSACTIONS parameter is greater than zero. If this parameter is zero, RECO is not created during instance startup.
Archiver (ARCH) The Archiver process (ARCH) copies online redo log files to a designated storage device once they become full. ARCH is present only when the redo log is used in ARCHIVELOG mode and automatic archiving is enabled. For information on archiving the online redo log, see Chapter 22, "Recovery Structures".
Additional Information: Details of using ARCH are operating system specific; for more information, see Oracle operating system-specific documentation.
Lock (LCKn) With the Parallel Server option, up to ten Lock processes (LCK0, . . ., LCK9) provide inter-instance locking. However, a single LCK process (LCK0) is sufficient for most Parallel Server systems. See Oracle7 Parallel Server Concepts & Administration for more information about this background process.
Snapshot Refresh (SNPn) With the distributed option, up to ten Snapshot Refresh processes (SNP0, ..., SNP9) can automatically refresh table snapshots. These processes wake up periodically and refresh any snapshots that are scheduled to be automatically refreshed. If more than one Snapshot Refresh process is used, the processes share the task of refreshing snapshots.
Dispatcher Processes (Dnnn) The Dispatcher processes allow user processes to share a limited number of server processes. Without a dispatcher, each user process requires one dedicated server process. However, with the multi-threaded server, fewer shared server processes are required for the same number of users. Therefore, in a system with many users, the multi-threaded server can support a greater number of users, particularly in client-server environments where the client application and server operate on different machines.
You can create multiple dispatcher processes for a single database instance; at least one dispatcher must be created for each network protocol used with Oracle. The database administrator should start an optimal number of dispatcher processes depending on the operating system limitation on the number of connections per process, and can add and remove dispatcher processes while the instance runs.
Note: The multi-threaded server requires SQL*Net Version 2 or later. Each user process that connects to a dispatcher must do so through SQL*Net, even if both processes are running on the same machine.
In a multi-threaded server configuration, a network listener process waits for connection requests from client applications, and routes each to a dispatcher process. If it cannot connect a client application to a dispatcher, the listener process starts a dedicated server process, and connects the client application to the dedicated server. This listener process is not part of an Oracle instance; rather, it is part of the networking processes that work with Oracle. See your SQL*Net documentation for more information about the network listener.
When an instance starts, the listener opens and establishes a communication pathway through which users connect to Oracle. Then, each dispatcher gives the listener an address at which the dispatcher listens for connection requests. When a user process makes a connection request, the listener process examines the request and determines if the user can use a dispatcher. If so, the listener process returns the address of the dispatcher process with the lightest load and the user process directly connects to the dispatcher.
Some user processes cannot communicate with the dispatcher (such as users connected using pre-Version 2 SQL*Net) and the network listener process cannot connect such users to a dispatcher. In this case, the listener creates a dedicated server and establishes an appropriate connection.
All filenames of trace files associated with a background process contain the name of the process that generated the trace file. The one exception to this is trace files generated by Snapshot Refresh processes.
ALTER SESSION SET SQL_TRACE = TRUE;
Each database also has an ALERT file. The ALERT file of a database is a chronological log of messages and errors, including
Virtual memory simulates memory using a combination of real (main) memory and secondary storage (usually disk space). The operating system accesses virtual memory by making secondary storage look like main memory to application programs.
Note: Usually, it is best to keep the entire SGA in real memory.
User programs can be shared or non-shared. Some Oracle tools and utilities, such as SQL*Forms and SQL*Plus, can be installed shared, but some cannot. Multiple instances of Oracle can use the same Oracle code area with different databases if running on the same computer.
Additional Information: Installing software shared is not an option for all operating systems; for example, it is not on PCs operating MS DOS. See your Oracle operating system-specific documentation for more information.
As described in "An Oracle Instance" , an SGA and Oracle processes constitute an Oracle instance. Oracle automatically allocates memory for an SGA when you start an instance and the memory is reclaimed when you shut down the instance. Each instance has its own SGA.
The SGA contains the following subdivisions:
With Release 7.3, the buffer cache and the shared SQL cache are logically segmented into multiple sets. This organization into multiple sets reduces contention on multiprocessor systems.
Organization of the Buffer Cache The buffers in the cache are organized in two lists: the dirty list and the least-recently-used (LRU) list. The dirty list holds dirty buffers. A dirty buffer is a buffer that has been modified but has not yet been written to disk. The least-recently-used (LRU) list holds free buffers, pinned buffers, and dirty buffers that have not yet been moved to the dirty list. Free buffers are buffers that have not been modified and are available for use. Pinned buffers are buffers that are currently being accessed.
When an Oracle process accesses a buffer, the process moves the buffer to the most-recently-used (MRU) end of the LRU list. As more buffers are continually moved to the MRU end of the LRU list, dirty buffers "age" towards the LRU end of the LRU list.
When a user process needs to access a block that is not already in the buffer cache, the process must read the block from a datafile on disk into a buffer in the cache. Before reading a block into the cache, the process must first find a free buffer. The process searches the LRU list, starting at the least-recently-used end of the list. The process searches either until it finds a free buffer or until it has searched the threshold limit of buffers.
As a user process searches the LRU list, it may find dirty buffers. If the user process finds a dirty buffer, it moves the buffer to the dirty list and continues to search. When a user process finds a free buffer, it reads the block into the buffer and moves it to the MRU end of the LRU list.
If an Oracle user process searches the threshold limit of buffers without finding a free buffer, the process stops searching the LRU list and signals the DBWR process to write some of the dirty buffers to disk. See "Database Writer (DBWR)" for more information about the DBWR background process.
Size of the Buffer Cache The initialization parameter DB_BLOCK_BUFFERS specifies the number of buffers in the database buffer cache. Each buffer in the cache is the size of one Oracle data block (specified by the initialization parameter DB_BLOCK_SIZE); therefore, each database buffer in the cache can hold a single data block read from a datafile.
The first time an Oracle user process accesses a piece of data, the process must copy the data from disk to the cache before accessing it. This is called a cache miss. When a process accesses a piece of data that is already in the cache, the process can read the data directly from memory. This is called a cache hit. Accessing data through a cache hit is faster than data access through a cache miss.
Since the cache has a limited size, all the data on disk cannot fit in the cache. When the cache is full, subsequent cache misses cause Oracle to write data already in the cache to disk to make room for the new data. Subsequent access to the data written to disk results in a cache miss.
The size of the cache affects the likelihood that a request for data will result in a cache hit. If the cache is large, it is more likely to contain the data that is requested. Increasing the size of a cache increases the percentage of data requests that result in cache hits.
You can prevent the default behavior of blocks involved in table scans on a table-by-table basis. To specify that blocks of the table are to be placed on the MRU end of the list during a full table scan, use the CACHE clause when creating or altering a table or cluster. You may want to specify this behavior for small lookup tables or large static historical tables to avoid I/O on subsequent accesses of the table.
Redo entries are copied by Oracle server processes from the user's memory space to the redo log buffer in the SGA. The redo entries take up continuous, sequential space in the buffer. The background process LGWR writes the redo log buffer to the active online redo log file group on disk. See "Log Writer (LGWR)" for more information about how the redo log buffer is written to disk.
Size of the Redo Log Buffer The initialization parameter LOG_BUFFER determines the size (in bytes) of redo log buffer. In general, larger values reduce log file I/O, particularly if transactions are long or numerous. The default setting is four times the maximum data block size for the host operating system.
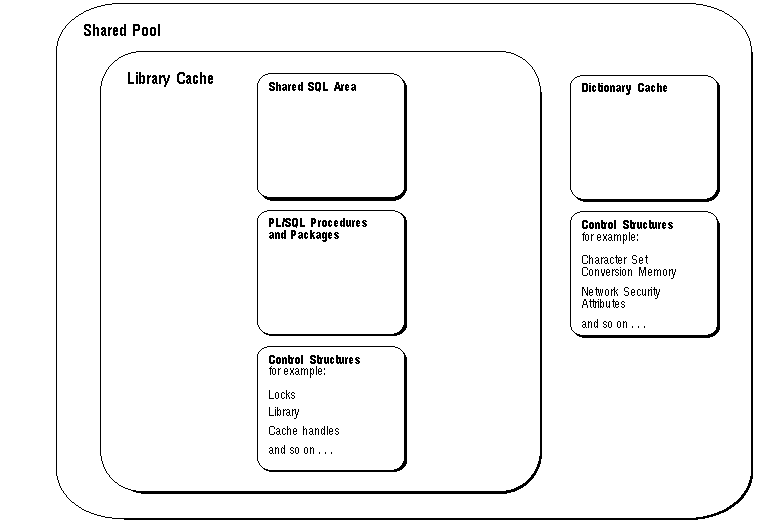
Figure 9 - 5. Contents of the Shared Pool
Library Cache The library cache includes shared SQL areas, private SQL areas, PL/SQL procedures and packages, and control structures such as locks and library cache handles.
Shared SQL Areas and Private SQL Areas Oracle represents each SQL statement it executes with a shared SQL area and a private SQL area. Oracle recognizes when two users are executing the same SQL statement and reuses the same shared part for those users. However, each user must have a separate copy of the statement's private SQL area.
A shared SQL area is a memory area that contains the parse tree and execution plan for a single SQL statement. Oracle allocates memory from the shared pool when a SQL statements is parsed and the size of this memory depends on the complexity of the statement. A shared SQL area is always in the shared pool and is shared for identical SQL statements. For more information about the criteria used to determine identical SQL statements, see "Shared SQL" .
A private SQL area is a memory area that contains data such as bind information and runtime buffers. Each session that issues a SQL statement has a private SQL area. Each user that submits an identical SQL statement has his/her own private SQL area that uses a single shared SQL area; many private SQL areas can be associated with the same shared SQL area.
A private SQL area has a persistent area and a runtime area:
persistent area
The persistent area contains bind information that persists across executions, code for datatype conversion (in case the defined datatype is not the same as the datatype of the selected column), and other state information (like recursive or remote cursor numbers or the state of a parallel query).The size of the persistent area depends on the number of binds and columns specified in the statement. For example, the persistent area is larger if many columns are specified in a query.
runtime area
The runtime area contains information used while the SQL statement is being executed. The size of the runtime area depends on the type and complexity of the SQL statement being executed and on the sizes of the rows that are processed by the statement. In general, the runtime area is somewhat smaller for INSERT, UPDATE, and DELETE statements than it is for SELECT statements.
The runtime area is created as the first step of an execute request. For INSERT, UPDATE, and DELETE statements, the runtime area is freed after the statement has been executed. For queries, the runtime area is freed only after all rows are fetched or the query is canceled.
For selects processing large amounts of data where sorts are needed, application developers should cancel the query if the client is satisfied with a partial result of a fetch. For example, in an Oracle Office application, a user can select from a list of over sixty templates for creating a mail message. Oracle Office displays the first ten template names and the user chooses one of these templates. The application can continue to try to display more template names, but because the user has chosen a template, the application should cancel the processing of the rest of the query.
The location of a private SQL area varies depending on the type of connection established for a session. If a session is connected via a dedicated server, private SQL areas are located in the user's PGA. However, if a session is connected via the multi-threaded server, the persistent areas and, for SELECT statements, the runtime areas, are kept in the SGA.
How the User Process Manages Private SQL Areas The management of private SQL areas is the responsibility of the user process. The allocation and deallocation of private SQL areas depends largely on which application tool you are using, although the number of private SQL areas that a user process can allocate is always limited by the initialization parameter OPEN_CURSORS. The default value of this parameter is 50.
How Oracle Manages Shared SQL Areas Since shared SQL areas must be available to multiple users, the library cache is contained in the shared pool within the SGA. The size of the library cache, along with the size of the data dictionary cache, is limited by the size of the shared pool. Memory allocation for shared pool is determined by the initialization parameter SHARED_POOL_SIZE. The default value for this parameter is 3.5 megabytes.
If a user process tries to allocate a shared SQL area after the entire shared pool has been allocated, Oracle can deallocate items from the pool using a modified least-recently-used algorithm until there is enough free space for the new item. If a shared SQL area is deallocated, the associated SQL statement must be reparsed and reassigned to another shared SQL area when it is next executed.
PL/SQL Program Units and the Shared Pool Oracle processes PL/SQL program units (procedures, functions, packages, anonymous blocks, and database triggers) similar to processing individual SQL statements. Oracle allocates a shared area to hold the parsed, compiled form of a program unit. Oracle allocates a private area to hold values specific to the session that executes the program unit, including local, global, and package variables (also known as package instantiation) and buffers for executing SQL. If more than one user executes the same program unit, then a single, shared area is used by all users, while each user maintains a separate copy of his/her private SQL area, holding values specific to his/her session.
Individual SQL statements contained within a PL/SQL program unit are processed as described in the previous sections. Despite their origins within a PL/SQL program unit, these SQL statements use a shared area to hold their parsed representations and a private area for each session that executes the statement.
Dictionary Cache The data dictionary is a collection of database tables and views containing reference information about the database, its structures, and its users. Among the data stored in the data dictionary are the following:
Since the data dictionary is accessed so often by Oracle, two special locations in memory are designated to hold dictionary data. One area is called the data dictionary cache, also know as the row cache. The other area in memory to hold dictionary data is in the library cache. The data dictionary caches are shared by all Oracle user processes.
When a SQL statement is submitted to Oracle for execution, there are some special steps to consider. On behalf of every SQL statement, Oracle automatically performs the following memory allocation steps:
If you change a database's global database name, all information is flushed from the shared pool. If desired, the administrator can manually flush all information in the shared pool to assess the performance (with respect to the shared pool, not the data buffer cache) that can be expected after instance startup without shutting down the current instance.
Cursors The application developer of an Oracle Precompiler program or OCI program can explicitly open cursors, or handles to specific private SQL areas, and use them as a named resource throughout the execution of the program. Each user session can open any number of cursors up to the limit set by the initialization parameter OPEN_CURSORS. However, applications should close unneeded cursors to conserve system memory. If a cursor cannot be opened due to a limit on the number of cursors, the database administrator can alter the OPEN_CURSORS initialization parameters. For more information about cursors, see "Cursors" .
Some statements (primarily DDL statements) require Oracle to implicitly issue recursive SQL statements, which also require recursive cursors. For example, a CREATE TABLE statement causes many updates to various data dictionary tables to record the new table and columns. Recursive calls are made for those recursive cursors; one cursor may execute several recursive calls. These recursive cursors also utilize shared SQL areas.
, and "Dispatcher Request and Response Queues" .)
The primary determinants of the size of the SGA are the parameters found in a database's parameter file. The parameters that most affect SGA size are the following:
DB_BLOCK_SIZE
The size, in bytes, of a single data block and database buffer.
DB_BLOCK_ BUFFERS
LOG_BUFFER
The number of bytes allocated for the redo log buffer.
SHARED_POOL_SIZE
The size in bytes of the area devoted to shared SQL and PL/SQL statements.
The memory allocated for an instance's SGA is displayed on instance startup when using Server Manager. You can also see the current instance's SGA size using the Server Manager command SHOW and the SGA option. See the Server Manager's User's Guide for more information about the Server Manager command SHOW, and the Oracle7 Server Administrator's Guide for discussions of the above initialization parameters and how they affect the SGA. See your installation or user's guide for information specific to your operating system.
Part of the SGA contains general information about the state of the database and the instance, which the background processes need to access; this is called the fixed SGA. No user data is stored here.
for more information about sessions. The contents of a PGA vary, depending on whether the associated instance is running the multi-threaded server. Figure 9 - 6 summarizes these differences.
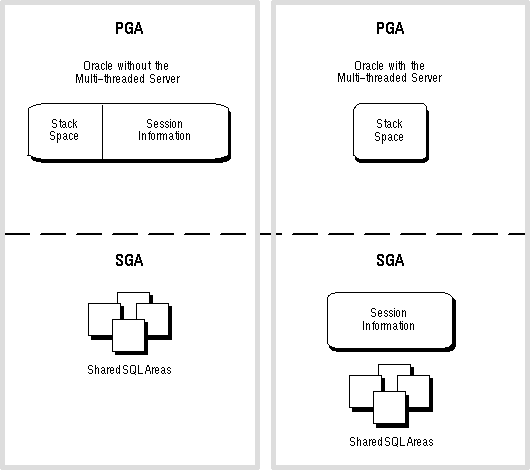
Figure 9 - 6. The Contents of a PGA with and without the Multi-Threaded Server
Stack Space A PGA always contains a stack space, which is memory allocated to hold a session's variables, arrays, and other information.
Session Information A PGA in an instance running without the multi-threaded server requires additional memory for the user's session, such as private SQL areas and other information. If the instance is running the multi-threaded server, this extra memory is not in the PGA, but is instead allocated in the SGA.
Shared SQL Areas Shared SQL areas are always in shared memory areas of the SGA (not the PGA), with or without the multi-threaded server.
The following initialization parameters affect the sizes of PGAs:
The size of the stack space in each PGA created on behalf of Oracle background processes (such as DBWR and LGWR) is affected by some additional parameters. See your Oracle operating system-specific documentation for more information.
If the amount of data to be sorted does not fit into a sort area, then the data is divided into smaller pieces that do fit. Each piece is then sorted individually. The individual sorted pieces are called "runs". After sorting all the runs, Oracle merges them to produce the final result.
If memory and temporary space are abundant on your system and you perform many large sorts to disk, the setting of the initialization parameter SORT_DIRECT_WRITES can increase sort performance.
For Release 7.3 and greater, the default value of SORT_DIRECT_WRITES is AUTO. If the initialization parameter is unspecified or set to AUTO, the database automatically allocates direct write buffers if the SORT_AREA_SIZE is ten times the minimum direct write buffer configuration. In this case, the sort allocates the direct write buffers out of a portion of the total sort area, ignoring the settings of SORT_WRITE_BUFFER_SIZE and SORT_WRITE_BUFFERS.
If you set SORT_DIRECT_WRITES to FALSE, the sorts that write to disk will write through the buffer cache. If you set the parameter to TRUE, each sort allocates additional buffers in memory for direct writes. You can set the initialization parameters SORT_WRITE_BUFFERS and SOFT_WRITE_BUFFER_SIZE to control the number and size of these buffers. The sort writes an entire buffer for each I/O operation. The Oracle process performing the sort writes the sort data directly to the disk, bypassing the buffer cache.
application or Oracle tool
Oracle server code
Each user has some Oracle server code executing on his/her behalf, which interprets and processes the application's SQL statements.
), but are very different in meaning. A connection is a communication pathway between a user process and an Oracle instance. A communication pathway is established using available inter-process communication mechanisms (on a computer that executes both the user process and Oracle) or network software (when different computers execute the database application and Oracle, and communicate via a network).
A session is a specific connection of a user to an Oracle instance via a user process; for example, when a user starts SQL*Plus, the user must provide a valid username and password and then a session is established for the user. A session lasts from the time the user connects until the time the user disconnects (or exits the database application).
Multiple sessions can be created and concurrently exist for a single Oracle user; for example, a user with the username/password of SCOTT/TIGER can connect to the same Oracle instance several times using the same username.
When the multi-threaded server is not used, a server process is created on behalf of each user session; however, when the multi-threaded server is used, a single server process can be shared among many user sessions; each of the following sections describes the relationship of sessions and processes with respect to the configuration variations.
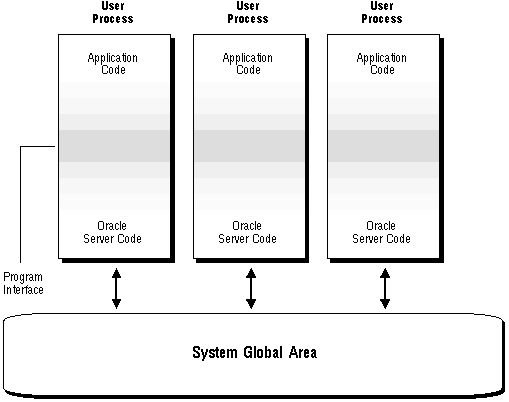
Figure 9 - 7. Oracle Using Combined User/Server Processes
This configuration of Oracle (sometimes called single-task Oracle) is only feasible in operating systems that can maintain a separation between the database application and the Oracle code in a single process (such as on the VAX VMS operating system). This separation is required for data integrity and privacy. Some operating systems, such as UNIX, cannot provide this separation and thus must have separate processes run application code from server code to prevent damage to Oracle by the application.
Note: The program interface is responsible for the separation and protection of the Oracle server code and is responsible for passing data between the database application and the Oracle user program. See "The Program Interface" for more information about this structure.
Only one Oracle connection is allowed at any time by a process using the above configuration. However, in a user-written program it is possible to maintain this type of connection while concurrently connecting to Oracle using a network (SQL*Net) interface.
Notice that in this type of system, a user process executes the database application on one machine and a server process executes the associated Oracle server on another machine. These two processes are separate, distinct processes. The separate server process created on behalf of each user process is called a dedicated server process (or shadow process) because this server process acts only on behalf of the associated user process.
In this configuration (sometimes called two-task Oracle), every user process connected to Oracle has a corresponding dedicated server process. Therefore, there is a one-to-one ratio between the number of user processes and server processes in this configuration. Even when the user is not actively making a database request, the dedicated server process remains (though it is inactive and may be paged out on some operating systems).
The dedicated server architecture of Oracle allows client applications being executed on client workstations to communicate with another computer running Oracle across a network. This is illustrated in Figure 9 - 8. However, this configuration of Oracle is also used if the same computer executes both the client application and the Oracle server code, but the host operating system cannot maintain the separation of the two programs if they were to be run in a single process. A common example of such an operating system is UNIX.
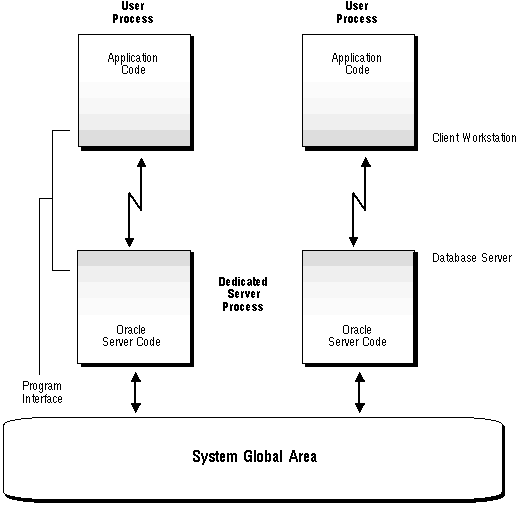
Figure 9 - 8. Oracle Using Dedicated Server Processes
The program interface allows the communication between the two programs. In the dedicated server configuration, communications between the user and server processes is accomplished using different mechanisms:
See "The Program Interface" for additional information about the program interface.
The multi-threaded server configuration eliminates the need for a dedicated server process for each connection. A small number of shared server processes can perform the same amount of processing as many dedicated server processes. Also, the amount of memory required for each user is relatively small. Because less memory and process management are required, more users can be supported.
Note: To use shared servers, a user process must connect through SQL*Net, even if the user process is on the same machine as the Oracle instance.
A request from a user is a single program interface call that is part of the user's SQL statement. When a user makes a call, its dispatcher places the request on the request queue in the SGA, where it is picked up by the next available shared server process. The shared server processes make all the necessary calls to the database to complete each user process's request. When the server completes the request, the server returns the results to the response queue of the dispatcher that the user is connected to the SGA. The dispatcher then returns the completed request to the user process.
In the order entry system example, each clerk's user process connects to a dispatcher; each request made by a clerk is sent to a dispatcher, which places the request in the request queue. The next available shared server process picks up the request, services it, and puts the response in the response queue. When a clerk's request is completed, the clerk remains connected to the dispatcher, but the shared server process that processed the request is released and available for other requests. While one clerk is talking to a customer, not making a request to the database, another clerk can use the same shared server process.
Figure 9 - 9 illustrates how user processes communicate with the dispatcher across the two-task interface and how the dispatcher communicates users' requests to shared server processes.
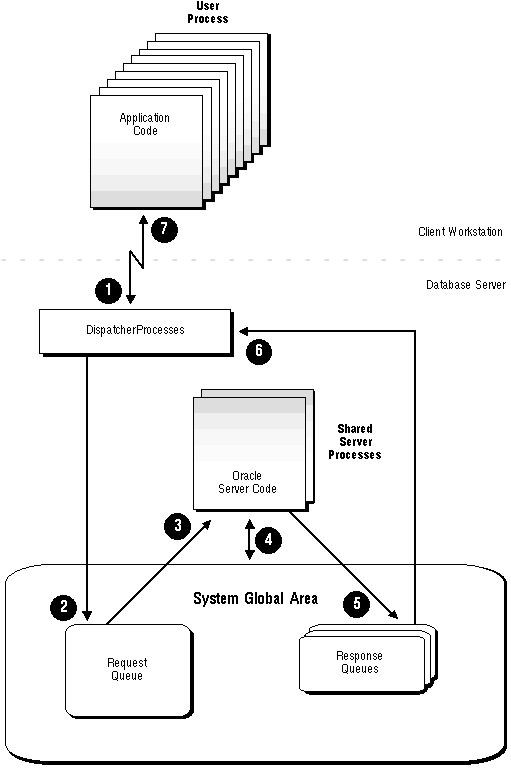
Figure 9 - 9. The Oracle Multi-Threaded Server Configuration and Shared Server Processes
The PGA of a shared server process does not contain user-related data; such information needs to be accessible to all shared server processes. The PGA of a shared server process contains only stack space and process-specific variables. "Program Global Area (PGA)" provides more information about the content of a PGA in different types of instance configurations.
All session-related information is contained in the SGA. Each shared server process needs to be able to access all sessions' data spaces so that any server can handle requests from any session. Space is allocated in the SGA for each session's data space. You can limit the amount of space that a session can allocate by setting the resource limit PRIVATE_SGA to the desired amount of space in the user's profile. See Chapter 17, "Database Access," for more information about resource limits and profiles.
Oracle dynamically adjusts the number of shared server processes based on the length of the request queue. The number of shared server processes that can be created ranges between the initialization parameters MTS_SERVERS and MTS_MAX_SERVERS.
If artificial deadlocks occur too frequently on your system, you should increase the value of MTS_MAX_SERVERS.
These activities are typically performed when connected as INTERNAL. When you want to connect as INTERNAL in system configured with multi-threaded servers, you must state in your connect string that you want to use a dedicated server process instead of a dispatcher process (SRVR=DEDICATED).
Additional Information: See your Oracle operating system-specific documentation or SQL*Net documentation for the proper connect string syntax.
You may install multiple drivers (such as the asynchronous or DECnet drivers), and select one as the default driver, but allow an individual user to use other drivers by specifying the desired driver at the time of connection. Different processes can use different drivers. A single process can have concurrent connections to a single database or to multiple databases (either local or remote) using different SQL*Net drivers.
The installation and configuration guide and SQL*Net documentation for your system contains details about choosing and installing drivers and adding new drivers after installation. The SQL*Net documentation describes selecting a driver at runtime while accessing Oracle.
Additional Information: The communication software may be supplied by Oracle Corporation but is usually purchased separately from the hardware vendor or a third party software supplier. See your Oracle operating system-specific documentation for more information about the communication software of your system.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |