| Oracle7 Server Concepts Manual | Library |
Product |
Contents |
Index |
| Oracle7 Server Concepts Manual | Library |
Product |
Contents |
Index |
![]()
![]()
Sir William Schwenck Gilbert: The Mikado
This chapter discusses the different types of objects contained in a user's schema. It includes:
Certain kinds of schema objects are discussed in more detail elsewhere in this manual. Specifically, procedures, functions, and packages are discussed in Chapter 14, "Procedures and Packages", database triggers in Chapter 15, "Database Triggers, and snapshots are covered in Chapter 21, "Distributed Databases".
If you are using Trusted Oracle, see the Trusted Oracle7 Server Administrator's Guide for additional information about schema objects in that environment.
Schema objects are logical data storage structures. Schema objects do not have a one-to-one correspondence to physical files on disk that store their information. However, Oracle stores a schema object logically within a tablespace of the database. The data of each object is physically contained in one or more of the tablespace's datafiles. For some objects such as tables, indexes, and clusters, you can specify how much disk space Oracle allocates for the object within the tablespace's datafiles. Figure 5 - 1 illustrates the relationship among objects, tablespaces, and datafiles.
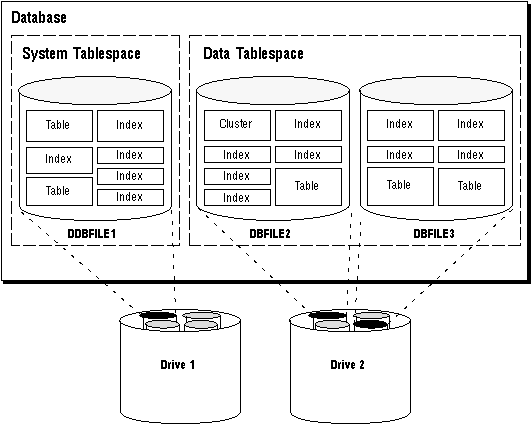
Figure 5 - 1. Schema Objects, Tablespaces, and Datafiles
There is no relationship between schemas and tablespaces: a tablespace can contain objects from different schemas, and the objects for a schema can be contained in different tablespaces.
Note: See Chapter 6, "Datatypes", for a discussion of the Oracle datatypes.
You can optionally specify rules for each column of a table. These rules are called integrity constraints. One example is a NOT NULL integrity constraint. This constraint forces the column to contain a value in every row. See Chapter 7, "Data Integrity", for more information about integrity constraints.
Once you create a table, you insert rows of data using SQL statements. Table data can then be queried, deleted, or updated using SQL.
Figure 5 - 2 shows a table named EMP.
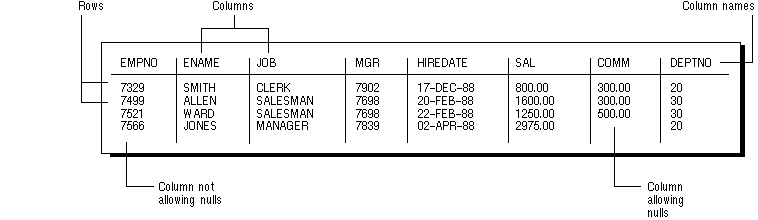
Figure 5 - 2. The EMP Table
The tablespace that contains a non-clustered table's data segment is either the table owner's default tablespace or a tablespace specifically named in the CREATE TABLE statement. See "User Tablespace Settings and Quotas" ![[*]](jump.gif) .
.
.Each row piece, chained or unchained, contains a row header and data for all or some of the row's columns. Individual columns might also span row pieces and, consequently, data blocks. Figure 5 - 3 shows the format of a row piece.
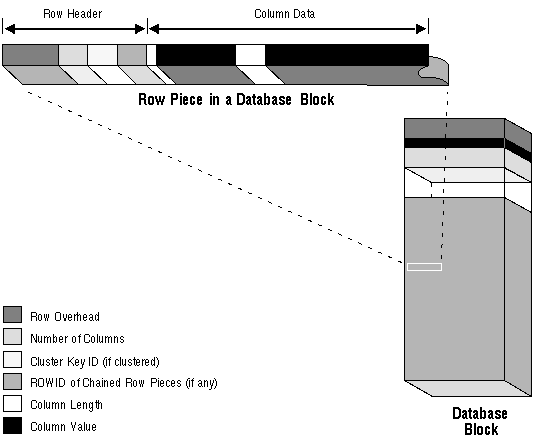
Figure 5 - 3. The Format of a Row Piece
The row header precedes the data and contains information about
To conserve space, a null in a column only stores the column length (zero). Oracle does not store data for the null column. Also, for trailing null columns, Oracle does not store the column length because the row header signals the start of a new row (for example, the last three columns of a table are null, thus there is no information stored for those columns).
Note: Each row uses two bytes in the data block header's row directory.
Clustered rows contain the same information as non-clustered rows. In addition, they contain information that references the cluster key to which they belong. See "Clusters" .
In general, you should try to place columns that frequently contain nulls last so that rows take less space. Note, though, that if the table you are creating includes a LONG column as well, the benefits of placing frequently null columns last are lost.
Because ROWIDs are constant for the lifetime of a row piece, it is useful to reference ROWIDs in SQL statements such as SELECT, UPDATE, and DELETE. See "ROWIDs and the ROWID Datatype" .
Nulls are stored in the database if they fall between columns with data values. In these cases they require one byte to store the length of the column (zero). Trailing nulls in a row require no storage because a new row header signals that the remaining columns in the previous row are null. In tables with many columns, the columns more likely to contain nulls should be defined last to conserve disk space.
Most comparisons between nulls and other values are by definition neither true nor false, but unknown. To identify nulls in SQL, use the IS NULL predicate. Use the SQL function NVL to convert nulls to non-null values. For more information about comparisons using IS NULL and the NVL function, see Oracle7 Server SQL Reference.
Nulls are not indexed, except when the cluster key column value is null.
Legal default values include any literal or expression that does not refer to a column, LEVEL, ROWNUM, or PRIOR. Default values can include the functions SYSDATE, USER, USERENV, and UID. The datatype of the default literal or expression must match or be convertible to the column datatype.
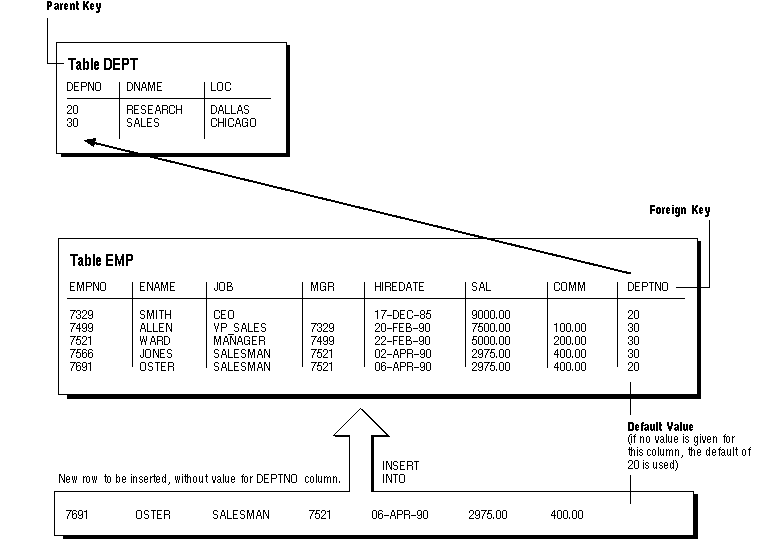
Figure 5 - 4. DEFAULT Column Values
For example, the EMP table has several columns and numerous rows of information. If you only want users to see five of these columns, or only specific rows, you can create a view of that table for other users to access. Figure 5 - 5 shows an example of a view called STAFF derived from the base table EMP. Notice that the view shows only five of the columns in the base table.
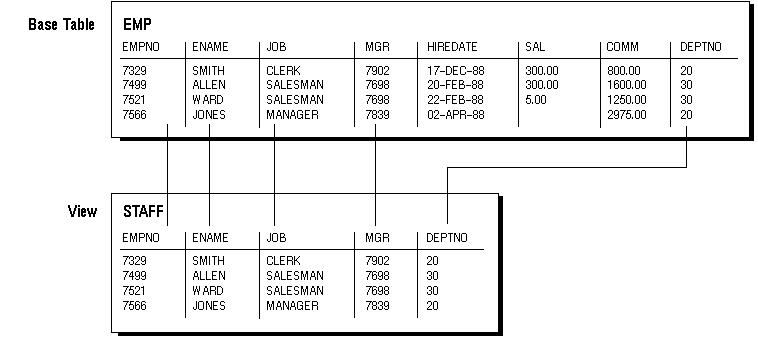
Figure 5 - 5. An Example of a View
Since views are derived from tables, many similarities exist between the two. For example, you can define views with up to 254 columns, just like a table. You can query views, and with some restrictions you can update, insert into, and delete from views. All operations performed on a view actually affect data in some base table of the view and are subject to the integrity constraints and triggers of the base tables.
Note: You cannot explicitly define integrity constraints and triggers on views, but you can define them for the underlying base tables referenced by the view.
For example, Figure 5 - 5 shows how the STAFF view does not show the SAL or COMM columns of the base table EMP.
For example, a single view might be defined with a join, which is a collection of related columns or rows in multiple tables. However, the view hides the fact that this information actually originates from several tables.
CREATE VIEW emp_view AS
SELECT empno, ename, sal, loc
FROM emp, dept
WHERE emp.deptno = dept.deptno AND dept.deptno = 10;
Now consider the following user-issued query:
SELECT ename
FROM emp_view
WHERE empno = 9876;
The final query constructed by Oracle is
SELECT ename
FROM emp, dept
WHERE emp.deptno = dept.deptno AND
dept.deptno = 10 AND
emp.empno = 9876;
In all possible cases, Oracle merges a query against a view with the view's defining query (and those of the underlying views). Oracle optimizes the merged query as if you issued the query without referencing the views. Therefore, Oracle can use indexes on any referenced base table columns, whether the columns are referenced in the view definition or the user query against the view.
In some cases, Oracle cannot merge the view definition with the user-issued query. In such cases, Oracle may not use all indexes on referenced columns.
An updatable join view is a join view, which involves two or more base tables or views, where UPDATE, INSERT, and DELETE operations are permitted. The data dictionary views, ALL_UPDATABLE_COLUMNS, DBA_UPDATABLE_COLUMNS, and USER_UPDATABLE_COLUMNS, contain information that indicates which of the view columns are updatable.
Table 5 - 1 lists rules for updatable join views.
For example, sales data for a calendar year may be broken up into four separate tables, one per quarter: Q1_SALES, Q2_SALES, Q3_SALES and Q4_SALES.
ALTER TABLE Q1_SALES ADD CONSTRAINT C0 check (sale_date between 'jan-1-1995' and 'mar-31-1995'); ALTER TABLE Q2_SALES ADD CONSTRAINT C1 check (sale_date between 'apr-1-1995' and 'jun-30-1995'); ALTER TABLE Q3_SALES ADD CONSTRAINT C2 check (sale_date between 'jul-1-1995' and 'sep-30-1995'); ALTER TABLE Q4_SALES ADD CONSTRAINT C3 check (sale_date between 'oct-1-1995' and 'dec-31-1995'); CREATE VIEW sales AS SELECT * FROM Q1_SALES UNION ALL SELECT * FROM Q2_SALES UNION ALL SELECT * FROM Q3_SALES UNION ALL SELECT * FROM Q4_SALES;
This method has several advantages. The check constraint predicates are not evaluated per row for queries. The predicates guard against inserting rows in the wrong partitions. It is easier to query the dictionary and find the partitioning criteria.
CREATE VIEW sales AS SELECT * FROM Q1_SALES WHERE sale_date between 'jan-1-1995' and 'mar-31-1995' UNION ALL SELECT * FROM Q2_SALES WHERE sale_date between 'apr-1-1995' and 'jun-30-1995' UNION ALL SELECT * FROM Q3_SALES WHERE sale_date between 'jul-1-1995' and 'sep-30-1995' UNION ALL SELECT * FROM Q4_SALES WHERE sale_date between 'oct-1-1995' and 'dec-31-1995';
This method has several drawbacks. First, the partitioning predicate is applied at runtime for all rows in all partitions that are not skipped. Second, if the user mistakenly inserts a row with sale_date = 'apr-4-1995' in Q1_SALES, the row will "disappear" from the partition view. Finally, the partitioning criteria are difficult to retrieve from the data dictionary because they are all embedded in one long view definition.
However, using WHERE clauses to define partition views has one advantage over using check constraints: the partition can be on a remote database with WHERE clauses. For example, you can use a WHERE clause to define a partition on a remote database as in this example:
SELECT * FROM eastern_sales@east.acme.com WHERE LOC = 'EAST' UNION ALL SELECT * FROM western_sales@west.acme.com WHERE LOC = 'WEST';
Because queries against eastern sales data do not need to fetch any western data, users will get increased performance. This cannot be done with constraints because the distributed query facility does not retrieve check constrains from remote databases.
SELECT orderno, value, custno FROM orders
WHERE order_date BETWEEN '30-JAN-95' AND '25-FEB-95'; This query involves just a few days of data for ORDERS_JAN and most of the data for ORDERS_FEB. Given this, the optimizer may come up with a plan that uses indexed access of ORDERS_JAN and a full scan of the table ORDERS_FEB. Examination of the remaining 10 partitions will be eliminated since the query does not involve them.
Partition views are especially useful in data warehouse environments where there is a common need to store and analyze large amounts of historical data.
For more performance implications when using sequences, see the Oracle7 Server Application Developer's Guide.
Synonyms are often used for security and convenience. For example, they can do the following:
Synonyms are very useful in both distributed and non-distributed database environments because they hide the identity of the underlying object, including its location in a distributed system. This is advantageous because if the underlying object must be renamed or moved, only the synonym needs to be redefined and applications based on the synonym continue to function without modification.
Synonyms can also simplify SQL statements for users in a distributed database system. The following example shows how and why public synonyms are often created by a database administrator to hide the identity of a base table and reduce the complexity of SQL statements. Assume the following:
SELECT * FROM jward.sales_data;
Notice how you must include both the schema that contains the table along with the table name to perform the query.
Assume that the database administrator creates a public synonym with the following SQL statement:
CREATE PUBLIC SYNONYM sales FOR jward.sales_data;
After the public synonym is created, you can query the table SALES_DATA with a simple SQL statement:
SELECT * FROM sales;
Notice that the public synonym SALES hides the name of the table SALES_DATA and the name of the schema that contains the table.
The absence or presence of an index does not require a change in the wording of any SQL statement. An index is merely a fast access path to the data; it affects only the speed of execution. Given a data value that has been indexed, the index points directly to the location of the rows containing that value.
Indexes are logically and physically independent of the data in the associated table. You can create or drop an index at anytime without effecting the base tables or other indexes. If you drop an index, all applications continue to work; however, access of previously indexed data might be slower. Indexes, as independent structures, require storage space.
Oracle automatically maintains and uses indexes once they are created. Oracle automatically reflects changes to data, such as adding new rows, updating rows, or deleting rows, in all relevant indexes with no additional action by users.
Oracle recommends that you do not explicitly define unique indexes on tables; uniqueness is strictly a logical concept and should be associated with the definition of a table. Alternatively, define UNIQUE integrity constraints on the desired columns. Oracle enforces UNIQUE integrity constraints by automatically defining a unique index on the unique key.
Composite indexes can speed retrieval of data for SELECT statements in which the WHERE clause references all or the leading portion of the columns in the composite index. Therefore, you should give some thought to the order of the columns used in the definition; generally, the most commonly accessed or most selective columns go first. For more information on composite indexes, see Oracle7 Server Tuning.
Figure 5 - 6 illustrates the VENDOR_PARTS table that has a composite index on the VENDOR_ID and PART_NO columns.

Figure 5 - 6. Indexes, Primary keys, Unique Keys, and Foreign Keys
No more than 16 columns can form the composite index, and a key value cannot exceed roughly one-half (minus some overhead) the available data space in a data block.
Integrity constraints enforce the business rules of a database; see Chapter 7, "Data Integrity". Because Oracle uses indexes to enforce some integrity constraints, the terms key and index are often are used interchangeably; however, they should not be confused with each other.
.
Additional Information: See your Oracle operating system-specific documentation for more information about the overhead of an index block.
When you create an index, Oracle fetches and sorts the columns to be indexed, and stores the ROWID along with the index value for each row. Then Oracle loads the index from the bottom up. For example, consider the statement:
CREATE INDEX emp_ename ON emp(ename);
Oracle sorts the EMP table on the ENAME column. It then loads the index with the ENAME and corresponding ROWID values in this sorted order. When it uses the index, Oracle does a quick search through the sorted ENAME values and then uses the associated ROWID values to locate the rows having the sought ENAME value.
Though Oracle accepts the keywords ASC, DESC, COMPRESS, and NOCOMPRESS in the CREATE INDEX command, they have no effect on index data, which is stored using rear compression in the branch nodes but not in the leaf nodes.
Figure 5 - 7. Internal Structure of a B*-Tree Index
The upper blocks (branch blocks) of a B*-tree index contain index data that points to lower level index blocks. The lowest level index blocks (leaf blocks) contain every indexed data value and a corresponding ROWID used to locate the actual row; the leaf blocks are doubly linked. Indexes in columns containing character data are based on the binary values of the characters in the database character set.
For a unique index, there is one ROWID per data value. For a non-unique index, the ROWID is included in the key in sorted order, so non-unique indexes are sorted by the index key and ROWID. Key values containing all nulls are not indexed, except for cluster indexes. Two rows can both contain all nulls and not violate a unique index.
The B*-tree structure has the following advantages:
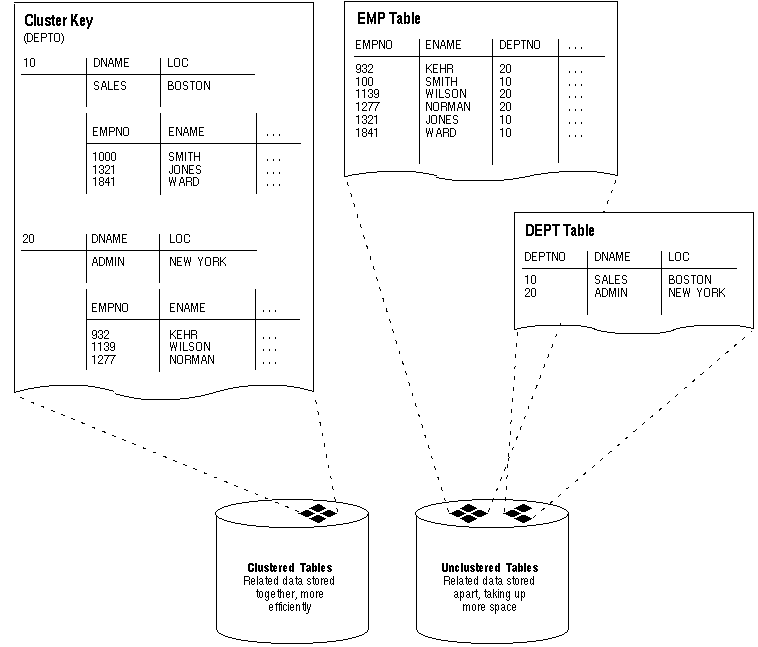
Figure 5 - 8. Clustered Table Data
Because clusters store related rows of different tables together in the same data blocks, properly used clusters offer two primary benefits:
To identify data that would be better stored in clustered form than non-clustered, look for tables that are related via referential integrity constraints and tables that are frequently accessed together using a join. If you cluster tables on the columns used to join table data, you reduce the number of data blocks that must be accessed to process the query; all the rows needed for a join on a cluster key are in the same block. Therefore, performance for joins is improved. Similarly, it might be useful to cluster an individual table. For example, the EMP table could be clustered on the DEPTNO column to cluster the rows for employees in the same department. This would be advantageous if applications commonly process rows department by department.
Like indexes, clusters do not affect application design. The existence of a cluster is transparent to users and to applications. You access data stored in a clustered table via SQL just like data stored in a non-clustered table.
For more information about the performance implications of using clusters, see Oracle7 Server Tuning.
For example, if each data block has 1700 bytes of available space and the specified cluster key size is 500 bytes, each data block can potentially hold rows for three cluster keys. If SIZE is greater than the amount of available space per data block, each data block holds rows for only one cluster key value.
Although the maximum number of cluster key values per data block is fixed by SIZE, Oracle does not actually reserve space for each cluster key value nor does it guarantee the number of cluster keys that are assigned to a block. For example, if SIZE determines that three cluster key values are allowed per data block, this does not prevent rows for one cluster key value from taking up all of the available space in the block. If more rows exist for a given key than can fit in a single block, the block is chained, as necessary.
A cluster key value is stored only once in a data block.
For each column specified as part of the cluster key (when creating the cluster), every table created in the cluster must have a column that matches the size and type of the column in the cluster key. No more than 16 columns can form the cluster key, and a cluster key value cannot exceed roughly one-half (minus some overhead) the available data space in a data block. The cluster key cannot include a LONG or LONG RAW column.
You can update the data values in clustered columns of a table. However, because the placement of data depends on the cluster key, changing the cluster key for a row might cause Oracle to physically relocate the row. Therefore, columns that are updated often are not good candidates for the cluster key.
You must create a cluster index before you can execute any DML statements (including INSERT and SELECT statements) against the clustered tables. Therefore, you cannot load data into a clustered table until you create the cluster index.
Like a table index, Oracle stores a cluster index in an index segment. Therefore, you can place a cluster in one tablespace and the cluster index in a different tablespace.
A cluster index is unlike a table index in the following ways:
Oracle uses a hash function to generate a distribution of numeric values, called hash values, which are based on specific cluster key values. The key of a hash cluster (like the key of an index cluster) can be a single column or composite key (multiple column key). To find or store a row in a hash cluster, Oracle applies the hash function to the row's cluster key value; the resulting hash value corresponds to a data block in the cluster, which Oracle then reads or writes on behalf of the issued statement.
A hash cluster is an alternative to a non-clustered table with an index or an index cluster. With an indexed table or index cluster, Oracle locates the rows in a table using key values that Oracle stores in a separate index.
To find or store a row in an indexed table or cluster, at least two I/Os must be performed (but often more): one or more I/Os to find or store the key value in the index, and another I/O to read or write the row in the table or cluster. In contrast, Oracle uses a hash function to locate a row in a hash cluster (no I/O is required). As a result, a minimum of one I/O operation is necessary to read or write a row in a hash cluster.
Note: In contrast, an index cluster stores related rows of clustered tables together based on each row's cluster key value.
When you create a hash cluster, Oracle allocates an initial amount of storage for the cluster's data segment. Oracle bases the amount of storage initially allocated for a hash cluster on the predicted number and predicted average size of the hash key's rows in the cluster.
Figure 5 - 9 illustrates data retrieval for a table in a hash cluster as well as a table with an index. The following sections further explain the internal operations of hash cluster storage.
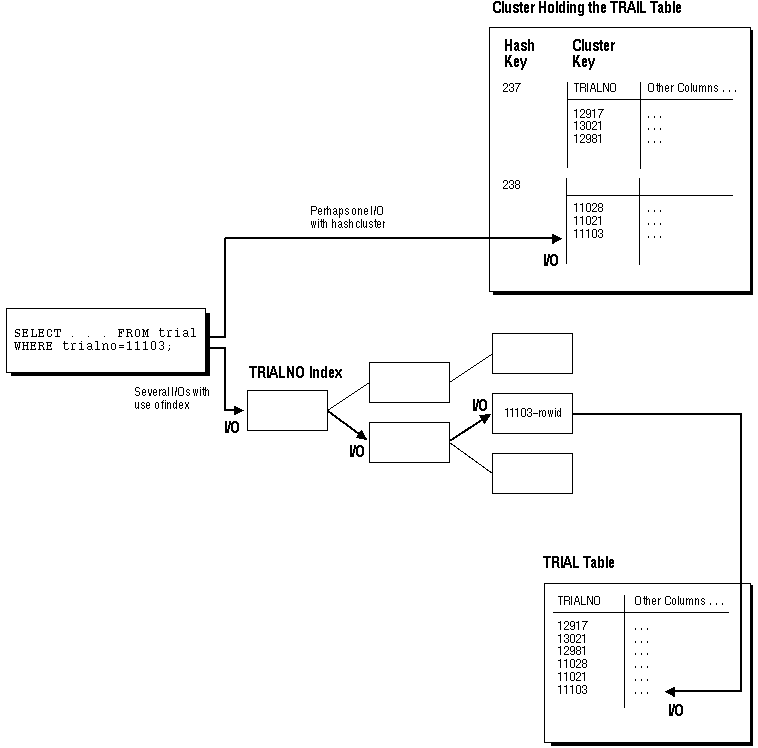
Figure 5 - 9. Hashing vs. Indexing: Data Storage and Information Retrieval
The value of HASHKEYS limits the number of unique hash values that can be generated by the hash function used for the cluster. Oracle rounds the number you specify for HASHKEYS to the nearest prime number. For example, setting HASHKEYS to 100 means that for any cluster key value, the hash function generates values between 0 and 100 (there will be 101 hash values).
Therefore, the distribution of rows in a hash cluster is directly controlled by the value set for the HASHKEYS parameter. With a larger number of hash keys for a given number of rows, the likelihood of a collision (two cluster key values having the same hash value) decreases. Minimizing the number of collisions is important because overflow blocks (thus extra I/O) might be necessary to store rows with hash values that collide.
Note: The importance of the SIZE parameter of hash clusters is analogous to that of the SIZE parameter for index clusters. However, with index clusters, SIZE applies to rows with the same cluster key value instead of the same hash value.
Although the maximum number of hash key values per data block is determined by SIZE, Oracle does not actually reserve space for each hash key value in the block. For example, if SIZE determines that three hash key values are allowed per block, this does not prevent rows for one hash key value from taking up all of the available space in the block. If there are more rows for a given hash key value than can fit in a single block, the block is chained, as necessary.
Note that each row's hash value is not stored as part of the row; however, the cluster key value for each row is stored. Therefore, when determining the proper value for SIZE, the cluster key value must be included for every row to be stored.
Furthermore, the cluster key can be comprised of columns of any datatype (except LONG and LONG RAW). The internal hash function offers sufficient distribution of cluster key values among available hash keys, producing a minimum number of collisions for any type of cluster key.
Instead of using the internal hash function to generate a hash value, Oracle checks the cluster key value. If the cluster key value is less than HASHKEYS, the hash value is the cluster key value; however, if the cluster key value is equal to or greater than HASHKEYS, Oracle divides the cluster key value by the number specified for HASHKEYS, and the remainder is the hash value; that is, the hash value is the cluster key value mod the number of hash keys.
Use the HASH IS parameter of the CREATE CLUSTER command to specify the cluster key column if cluster key values are distributed evenly throughout the cluster. The cluster key must be comprised of a single column that contains only zero scale numbers (integers). If the internal hash function is bypassed and a non-integer cluster key value is supplied, the operation (INSERT or UPDATE statement) is rolled back and an error is returned.
For example, if you have a hash cluster containing employee information and the cluster key is the employee's home area code, it is likely that many employees will hash to the same hash value. To alleviate this problem, you can place the following expression in the HASH IS clause of the CREATE CLUSTER command:
MOD((emp.home_area_code + emp.home_prefix + emp.home_suffix), 101)
The expression takes the area code column and adds the phone prefix and suffix columns, divides by the number of hash values (in this case 101), and then uses the remainder as the hash value. The result is cluster rows more evenly distributed among the various hash values.
Space subsequently allocated to a hash cluster is used to hold the overflow of rows from data blocks that are already full. For example, assume the original data block for a given hash key is full. A user inserts a row into a clustered table such that the row's cluster key hashes to the hash value that is stored in a full data block; therefore, the row cannot be inserted into the root block (original block) allocated for the hash key. Instead, the row is inserted into an overflow block that is chained to the root block of the hash key.
Frequent collisions might or might not result in a larger number of overflow blocks within a hash cluster (thus reducing data retrieval performance). If a collision occurs and there is no space in the original block allocated for the hash key, an overflow block must be allocated to hold the new row. The likelihood of this happening is largely dependent on the average size of each hash key value and corresponding data, specified when the hash cluster is created, as illustrated in Figure 5 - 10.
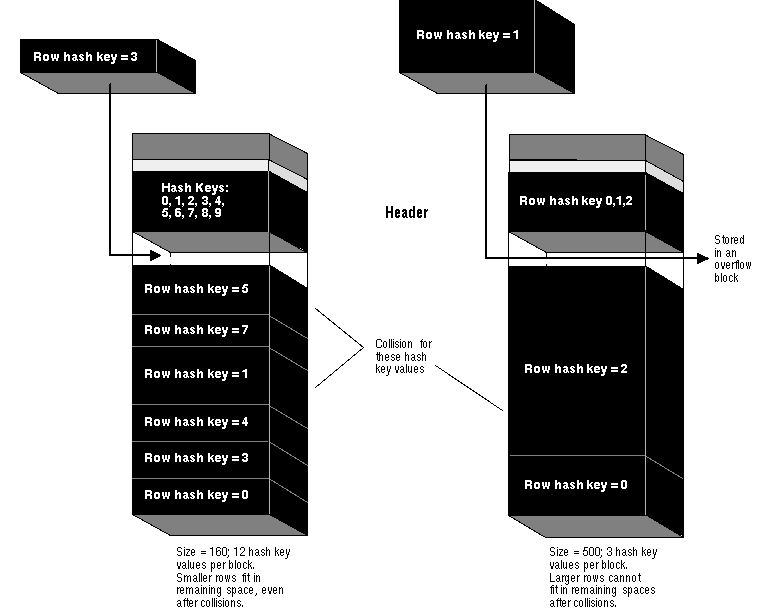
Figure 5 - 10. Collisions and Overflow Blocks in a Hash Cluster
If the average size is small and each row has a unique hash key value, many hash key values can be assigned per data block. In this case, a small colliding row can likely fit into the space of the root block for the hash key. However, if the average hash key value size is large or each hash key value corresponds to multiple rows, only a few hash key values can be assigned per data block. In this case, it is likely that the large row will not be able to fit in the root block allocated for the hash key value and an overflow block is allocated.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |