| Oracle7 Server Concepts Manual | Library |
Product |
Contents |
Index |
| Oracle7 Server Concepts Manual | Library |
Product |
Contents |
Index |
![]()
![]()
Franklin Delano Roosevelt
This chapter introduces the structures of Oracle that are used during database recovery. It includes:
The procedures necessary to create and maintain these structures are discussed in the Oracle7 Server Administrator's Guide.
Recovery processes vary depending on the type of failure that occurred, the structures affected, and the type of recovery that you perform. If no files are lost or damaged, recovery may amount to no more than restarting an instance. If data has been lost, recovery requires additional steps, as described in Chapter 24, "Database Recovery".
Recovery from instance failure is relatively automatic. For example, in configurations that do not use the Oracle Parallel Server, the next instance startup automatically performs instance recovery. When using the Oracle Parallel Server, other instances perform instance recovery. For additional information about instance recovery, see Chapter 24, "Database Recovery".
A common example of a media failure is a disk head crash, which causes the loss of all files on a disk drive. All files associated with a database are vulnerable to a disk crash, including datafiles, redo log files, and control files. The appropriate recovery from a media failure depends on the files affected; see Chapter 24, "Database Recovery", for a discussion of media recovery.
How Media Failures Affect Database Operation Media failures can affect one or all types of files necessary for the operation of an Oracle database, including datafiles, online redo log files, and control files.
Database operation after a media failure of online redo log files or control files depends on whether the online redo log or control file is multiplexed, as recommended. A multiplexed online redo log or control file simply means that a second copy of the file is maintained. If a media failure damages a single disk, and you have a multiplexed online redo log, the database can usually continue to operate without significant interruption. Damage to a non-multiplexed online redo log causes database operation to halt and may cause permanent loss of data. Damage to any control file, whether it is multiplexed or non-multiplexed, halts database operation once Oracle attempts to read or write the damaged control file.
Media failures that affect datafiles can be divided into two categories: read errors and write errors. In a read error, Oracle discovers it cannot read a datafile and an operating system error is returned to the application, along with an Oracle error indicating that the file cannot be found, cannot be opened, or cannot be read. Oracle continues to run, but the error is returned each time an unsuccessful read occurs. At the next checkpoint, a write error will occur when Oracle attempts to write the file header as part of the standard checkpoint process.
If Oracle discovers that it cannot write to a datafile and Oracle archives filled online redo log files, Oracle returns an error in the DBWR trace file, and Oracle takes the datafile offline automatically. Only the datafile that cannot be written to is taken offline; the tablespace containing that file remains online.
If the datafile that cannot be written to is in the SYSTEM tablespace, the file is not taken offline. Instead, an error is returned and Oracle shuts down the database. The reason for this exception is that all files in the SYSTEM tablespace must be online in order for Oracle to operate properly. For the same reason, the datafiles of a tablespace containing active rollback segments must remain online.
If Oracle discovers that it cannot write to a datafile, and Oracle is not archiving filled online redo log files, DBWR fails and the current instance fails. If the problem is temporary (for example, the disk controller was powered off), instance recovery usually can be performed using the online redo log files, in which case the instance can be restarted. However, if a datafile is permanently damaged and archiving is not used, the entire database must be restored using the most recent backup.
Oracle offers several options in performing database backups; see Chapter 23, "Database Backup", for more information.
A database's redo log can be comprised of two parts: the online redo log and the archived redo log, discussed in the following sections.
The Online Redo Log Every Oracle database has an associated online redo log. The online redo log works with the Oracle background process LGWR to immediately record all changes made through the associated instance. The online redo log consists of two or more pre-allocated files that are reused in a circular fashion to record ongoing database changes; see "The Online Redo Log" ![[*]](jump.gif) for more information.
for more information.
The Archived (Offline) Redo Log Optionally, you can configure an Oracle database to archive files of the online redo log once they fill. The online redo log files that are archived are uniquely identified and make up the archived redo log. By archiving filled online redo log files, older redo log information is preserved for more extensive database recovery operations, while the pre-allocated online redo log files continue to be reused to store the most current database changes; see "The Archived Redo Log" page 22-16 for more information.
for more information.
for more information.
Note: Redo entries store low-level representations of database changes that cannot be mapped to user actions. Therefore, the contents of an online redo log file should never be edited or altered, and cannot be used for any application purposes such as auditing.
Redo entries are buffered in a "circular" fashion in the redo log buffer of the SGA and are written to one of the online redo log files by the Oracle background process Log Writer (LGWR). Whenever a transaction is committed, LGWR writes the transaction's redo entries from the redo log buffer of the SGA to an online redo log file, and a system change number (SCN) is assigned to identify the redo entries for each committed transaction.
However, redo entries can be written to an online redo log file before the corresponding transaction is committed. If the redo log buffer fills, or another transaction commits, LGWR flushes redo log entries in the redo log buffer to an online redo log file, of which some redo entries may not be committed. See "The Redo Log Buffer" for more information.
LGWR writes to online redo log files in a circular fashion; when the current online redo log file is filled, LGWR begins writing to the next available online redo log file. When the last available online redo log file is filled, LGWR returns to the first online redo log file and writes to it, starting the cycle again. Figure 22 - 1 illustrates the circular writing of the online redo log file. The numbers next to each line indicate the sequence in which LGWR writes to each online redo log file.
Filled online redo log files are "available" to LGWR for reuse depending on whether archiving is enabled:

Figure 22 - 1. Circular Use of Online Redo Log Files by LGWR
Online redo log files that are required for instance recovery are called active online redo log files. Online redo log files that are not required for instance recovery are called inactive.
If archiving is enabled, an active online log file cannot be reused or overwritten until its contents are archived. If archiving is disabled, when the last online redo log file fills, writing continues by overwriting the first available active file. For more information about archiving options for the redo log, see "Database Archiving Modes" on page 22-18.
Oracle assigns each online redo log file a new log sequence number every time that a log switch occurs and LGWR begins writing to it. If online redo log files are archived, the archived redo log file retains its log sequence number. The online redo log file that is cycled back for use is given the next available log sequence number.
Each redo log file (including online and archived) is uniquely identified by its log sequence number. During instance or media recovery, Oracle properly applies redo log files in ascending order by using the log sequence number of necessary archived and online redo log files.
Checkpoints occur whether or not filled online redo log files are archived. If archiving is disabled, a checkpoint affecting an online redo log file must complete before the online redo log file can be reused by LGWR. If archiving is enabled, a checkpoint must complete and the filled online redo log file must be archived before it can be reused by LGWR.
Checkpoints can occur for all datafiles of the database (called database checkpoints) or can occur for only specific datafiles. The following list explains when checkpoints occur and what type happens in each situation:
The Mechanics of a Checkpoint When a checkpoint occurs, the checkpoint background process (CKPT) remembers the location of the next entry to be written in an online redo log file and signals the database writer background process (DBWR) to write the modified database buffers in the SGA to the datafiles on disk. CKPT then updates the headers of all control files and datafiles to reflect the latest checkpoint.
When a checkpoint is not happening, DBWR only writes the least-recently-used database buffers to disk to free buffers as needed for new data. However, as a checkpoint proceeds, DBWR writes data to the data files on behalf of both the checkpoint and ongoing database operations. DBWR writes a number of modified data buffers on behalf of the checkpoint, then writes the least recently used buffers, as needed, and then writes more dirty buffers for the checkpoint, and so on, until the checkpoint completes.
Depending on what signals a checkpoint to happen, the checkpoint can be either "normal" or "fast". With a normal checkpoint, DBWR writes a small number of data buffers each time it performs a write on behalf of a checkpoint. With a fast checkpoint, DBWR writes a large number of data buffers each time it performs a write on behalf of a checkpoint.
Therefore, by comparison, a normal checkpoint requires more I/Os to complete than a fast checkpoint. Because a fast checkpoint requires fewer I/Os, the checkpoint completes very quickly. However, a fast checkpoint can also detract from overall database performance if DBWR has a lot of other database work to complete. Events that trigger normal checkpoints include log switches and checkpoint intervals set by initialization parameters; events that trigger fast checkpoints include online tablespace backups, instance shutdowns, and database administrator-forced checkpoints.
Until a checkpoint completes, all online redo log files written since the last checkpoint are needed in case a database failure interrupts the checkpoint and instance recovery is necessary. Additionally, if LGWR cannot access an online redo log file for writing because a checkpoint has not completed, database operation suspends temporarily until the checkpoint completes and an online redo log file becomes available. In this case, the normal checkpoint becomes a fast checkpoint, so it completes as soon as possible.
For example, if only two online redo log files are used, and LGWR requires another log switch, the first online redo log file is unavailable to LGWR until the checkpoint for the previous log switch completes.
Note: The information that is recorded in the datafiles and control files as part of a checkpoint varies if the Oracle Parallel Server configuration is used; see Oracle7 Parallel Server Concepts & Administration.
You can set the initialization parameter LOG_CHECKPOINTS_TO_ALERT to determine if checkpoints are occurring at the desired frequency. The default value of NO for this parameter does not log checkpoints. When you set the parameter to YES, information about each checkpoint is recorded in the ALERT file.
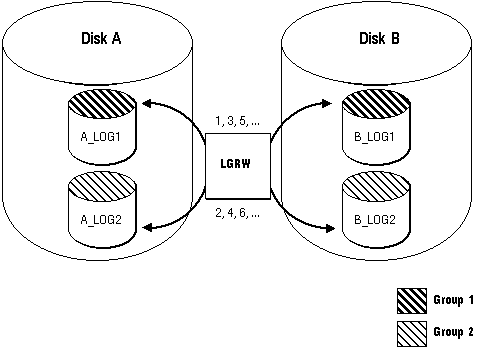
Figure 22 - 2. Multiplexed Online Redo Log Files
The corresponding online redo log files are called groups. Each online redo log file in a group is called a member. Notice that all members of a group are concurrently active (concurrently written to by LGWR), as indicated by the identical log sequence numbers assigned by LGWR. If a multiplexed online redo log is used, each member in a group must be the exact same size.
The Mechanics of a Multiplexed Online Redo Log LGWR always addresses all members of a group, whether the group contains one or many members. For example, LGWR always tries to write to all members of a given group concurrently, then to switch and concurrently write to all members of the next group, and so on. LGWR never writes concurrently to one member of a given group and one member of another group.
LGWR reacts differently when certain online redo log members are unavailable, depending on the reason for the file(s) being unavailable:
To always safeguard against a single point of online redo log failure, a multiplexed online redo log should be completely symmetrical: all groups of the online redo log should have the same number of members. However, Oracle does not require that a multiplexed online redo log be symmetrical. For example, one group can have only one member, while other groups can have two members. Oracle allows this behavior to provide for situations that temporarily affect some online redo log members but leave others unaffected (for example, a disk failure). The only requirement for an instance's online redo log, multiplexed or non-multiplexed, is that it be comprised of at least two groups. Figure 22 - 3 shows a legal and illegal multiplexed online redo log configuration.
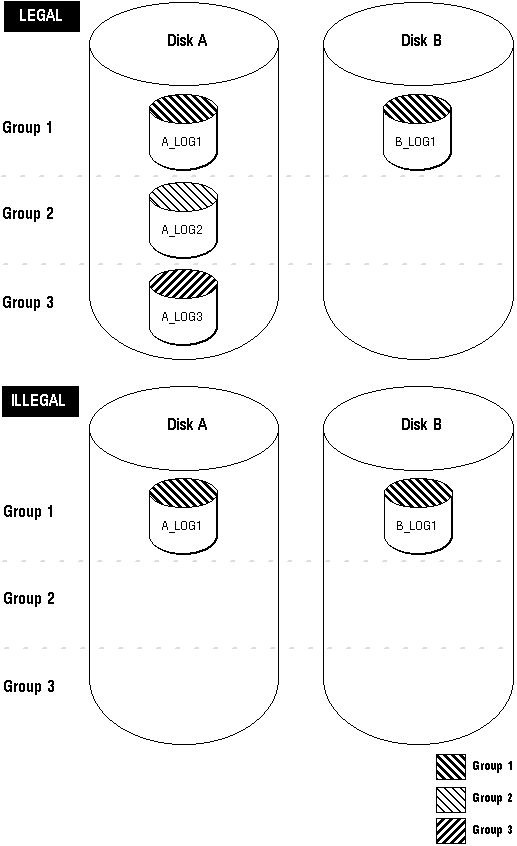
Figure 22 - 3. Legal and Illegal Multiplexed Online Redo Log Configuration
This manual describes how to configure and manage the online redo log when the Oracle Parallel Server is not used. The thread number can be assumed to be 1 in all discussions and examples of commands. For complete information about configuring the online redo log with the Oracle Parallel Server, see Oracle7 Parallel Server Concepts & Administration.
and "Manual Archiving" .Note: For simplicity, the remainder of this section assumes that archiving is enabled and the ARCH background process is responsible for archiving filled online redo log groups.
ARCH can archive a group once the group becomes inactive and the log switch to the next group has completed. The ARCH process can access any members of the group, as needed, to complete the archiving of the group. For example, if ARCH attempts to open a member of a group and it is not accessible (for example, due to a disk failure), ARCH automatically tries to use another member of the group, and so on, until it finds a member of the group that is available for archiving. If ARCH is archiving a member of a group, and the information in the member is detected as invalid or a disk failure occurs as archiving proceeds, ARCH automatically switches to another member of the group to continue archiving the group where it was interrupted.
When archiving is used, an archiving destination is specified. This destination is usually a storage device separate from the disk drives that hold the datafiles, online redo log files, and control files of the database. Typically, the archiving destination is another disk drive of the database server This way, archiving does not contend with other files required by the instance and completes quickly so the group can become available to LGWR. Ideally, archived redo log files (and corresponding database backups) should be moved permanently to inexpensive offline storage media, such as tape, that can be stored in a safe place, separate from the database server.
At log switch time, when no more information will be written to a redo log, a record is created in the database's control file. Each record contains the thread number, log sequence number, low SCN for the group, and next SCN after the archived log file; this information is used during database recovery in Parallel Server configurations to automate the application of redo log files. See Oracle7 Parallel Server Concepts & Administration for additional information.
If archiving is enabled, LGWR is not allowed to reuse an online redo log group until it has been archived. Therefore, it is guaranteed that the archived redo log contains a copy of every group (uniquely identified by log sequence numbers) created since archiving was enabled.
NOARCHIVELOG mode protects a database only from instance failure, not from disk (media) failure. Only the most recent changes made to the database, stored in the groups of the online redo log, are available for instance recovery.
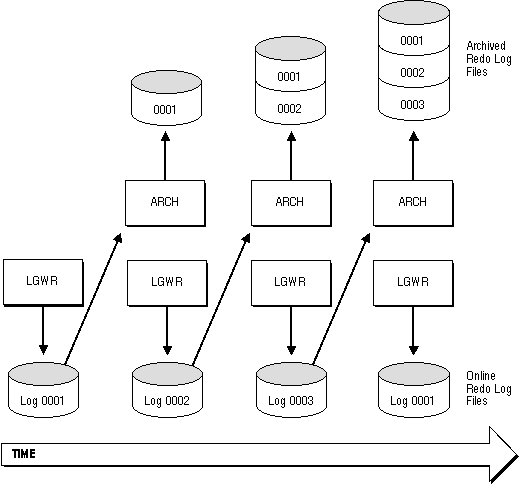
Figure 22 - 4. Online Redo Log File Use in ARCHIVELOG Mode
ARCHIVELOG mode permits complete recovery from disk failure as well as instance failure, because all changes made to the database are permanently saved in an archived redo log.
Automatic Archiving and the ARCH (Archiver) Background Process An instance can be configured to have an additional background process, Archiver (ARCH), automatically archive groups of online redo log files once they become inactive. Therefore, automatic archiving frees the database administrator from having to keep track of, and archive, filled groups manually. For this convenience alone, automatic archiving is the choice of most database systems that have an archived redo log.
If you request automatic archiving at instance startup by setting the LOG_ARCHIVE_START initialization parameter, Oracle starts ARCH during instance startup. Otherwise, ARCH is not started during instance startup.
However, the database administrator can interactively start or stop automatic archiving at any time. If automatic archiving was not specified to start at instance startup, and the administrator subsequently starts automatic archiving, the ARCH background process is created. ARCH then remains for the duration of the instance, even if automatic archiving is temporarily turned off and turned on again.
ARCH always archives groups in order, beginning with the lowest sequence number. ARCH automatically archives filled groups as they become inactive. A record of every automatic archival is written in the ARCH trace file by the ARCH process. Each entry shows the time the archive started and stopped.
If ARCH encounters an error when attempting to archive a group (for example, due to an invalid or filled destination), ARCH continues trying to archive the group. An error is also written in the ARCH trace file and the ALERT file. If the problem is not resolved, eventually all online redo log groups become full, yet not archived, and the system halts because no group is available to LGWR. Therefore, if problems are detected, you should either resolve the problem so that ARCH can continue archiving (such as by changing the archive destination) or manually archive groups until the problem is resolved.
Manual Archiving If a database is operating in ARCHIVELOG mode, the database administrator can manually archive the filled groups of inactive online redo log files, as necessary, whether or not automatic archiving is enabled or disabled. If automatic archiving is disabled, the database administrator is responsible for archiving all filled groups.
Each control file is associated with only one Oracle database.
Among other things, a control file contains information such as
for information about backing up a database's control file.
Control files also record information about checkpoints. When a checkpoint starts, the control file records information to remember the next entry that must be entered into the online redo log. This information is used during database recovery to tell Oracle that all redo entries recorded before this point in the online redo log group are not necessary for database recovery; they were already written to the datafiles. See "Checkpoints" .
The permanent loss of all copies of a database's control file is a serious problem to safeguard against. If all control files of a database are permanently lost during operation (several disks fail), the instance is aborted and media recovery is required. Even so, media recovery is not straightforward if an older backup of a control file must be used because a current copy is not available. Therefore, it is strongly recommended that multiplexed control files be used with each database, with each copy stored on a different physical disk.
For information about creating and maintaining a standby database, see the Oracle7 Server Administrator's Guide.
See Chapter 24, "Database Recovery", for information about recovering a database.
A standby database involves two databases: a primary database and a standby database. The primary database is the production database that is in use. The standby database is a copy of the production database, ideally located on a separate machine. The standby database runs in recovery mode until there is a failure at the primary site. At the time of a failure, the standby database performs recovery operations and comes online as the primary database.
A standby database uses the archived log information from the primary database, so it is ready to perform recovery and go online at any time. When the primary database archives its redo logs, the logs must be transferred to the remote site and applied to the standby database. The standby database is therefore always behind the primary database in time and transaction history.
The physical hardware on which the standby database resides should be used only as a disaster recovery system; no other applications should run on it. Because the standby database is designed for disaster recovery, it ideally resides in a separate physical location than the primary. The standby database exists not only to guard against power failures and hardware failures, but also to protect your data in the event of a physical disaster such as a fire or an earthquake.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |