

Database Recovery
Turn back, O man,
Forswear thy foolish ways.
Old now is Earth and none may count her days.
Da da da da da.
Steven Schwartz: Godspell
This chapter discusses the database recovery from instance and media failures. It includes:
Recovery Procedures
In every database system, the possibility of a system failure is always present. Should system failure occur, you must recover the database as quickly, and with as little detrimental impact on users, as possible.
Recovering from any type of system failure requires the following:
1. Determining which data structures are intact and which ones
need recovery.
2. Following the appropriate recovery steps.
3. Restarting the database so that it can resume normal operations.
4. Ensuring that no work has been lost nor incorrect data entered in the database.
The goal is to return to normal as quickly as possible while insulating database users from any problems and the possibility of losing or duplicating work.
The recovery process varies depending on the type of failure and the files of the database affected by the failure.
Recovery Features
Oracle offers several features to provide flexibility in recovery strategies:
- recovery from system, software, or hardware failure
- automatic database instance recovery at database start up
- recovery of individual offline tablespaces or files while the rest of a database is operational
- time-based and change-based recovery operations to recover to a transaction-consistent state specified by the database administrator
- increased control over recovery time in the event of system failure
- the ability to apply redo log entries in parallel to reduce the amount of time for recovery
- Export and Import utilities for archiving and restoring data in a logical data format, rather than a physical file backup
An Introduction to Database Recovery
The following sections provide a brief summary of how Oracle writes information to the datafiles. This discussion introduces the recovery structures and processes necessary to recover a database from any type of failure.
For instructions on performing database recovery, see the Oracle7 Server Administrator's Guide.
Database Buffers and DBWR
Database buffers in the SGA are written to disk only when necessary, using the least-recently-used algorithm. Because of the way that DBWR uses this algorithm to write database buffers to datafiles, datafiles might contain some data blocks modified by uncommitted transactions and some data blocks missing changes from committed transactions.
Two potential problems can result if an instance failure occurs:
- Data blocks modified by a transaction might not be written to the datafiles at commit time and might only appear in the redo log. Therefore, the redo log contains changes that must be reapplied to the database during recovery.
- Since the redo log might have also contained data that was not committed, the uncommitted transaction changes applied by the redo log (as well as any uncommitted changes applied by earlier redo logs) must be erased from the database.
To solve this dilemma, two separate steps are generally used by Oracle for a successful recovery of a system failure: rolling forward with the redo log and rolling back with the rollback segments.
The Redo Log and Rolling Forward
The redo log is a set of operating system files that record all changes made to any database buffer, including data, index, and rollback segments, whether the changes are committed or uncommitted. The redo log protects changes made to database buffers in memory that have not been written to the datafiles.
The first step of recovery from an instance or disk failure is to roll forward, or reapply all of the changes recorded in the redo log to the datafiles. Because rollback data is also recorded in the redo log, rolling forward also regenerates the corresponding rollback segments.
Rolling forward proceeds through as many redo log files as necessary to bring the database forward in time. Rolling forward usually includes online redo log files and may include archived redo log files.
After roll forward, the data blocks contain all committed changes as well as any uncommitted changes that were recorded in the redo log.
Rollback Segments and Rolling Back
Rollback segments record database actions that should be undone during certain database operations. In database recovery, rollback segments undo the effects of uncommitted transactions previously applied by the rolling forward phase.
After the roll forward, any changes that were not committed must be undone. After redo log files have reapplied all changes made to the database, then the corresponding rollback segments are used. Rollback segments are used to identify and undo transactions that were never committed, yet were recorded in the redo log and applied to the database during roll forward. This process is called rolling back.
Figure 24 - 1 illustrates rolling forward and rolling back, the two steps necessary to recover from any type of system failure.
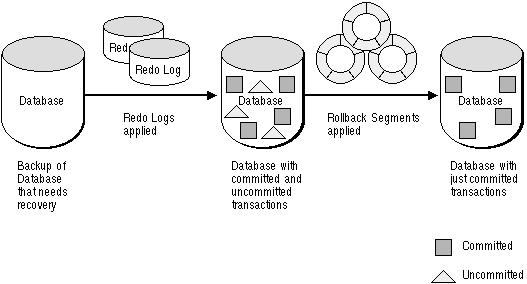
Figure 24 - 1. Basic Recovery Steps: Rolling Forward and Rolling Back
Starting with release 7.3, Oracle can roll back multiple transactions simultaneously as needed. All transactions system-wide that were active at the time of failure are marked as DEAD. Instead of waiting for SMON to roll back dead transactions, new transactions can recover blocking transactions themselves to get the row locks they need. This feature is called fast transaction rollback.
Performing Recovery in Parallel
Recovery reapplies the changes generated by several concurrent processes, and therefore instance or media recovery can take longer than the time it took to initially generate the changes to a database. With serial recovery, a single process applies the changes in the redo log files sequentially. Using parallel recovery, several processes can simultaneously apply changes from the redo log files.
One form of parallel recovery can be performed by spawning several Server Manager sessions and issuing the RECOVER DATAFILE command on a different set of datafiles in each session. However, this method causes each Server Manager session to read the entire redo log file.
Instance and media recovery can be parallelized automatically by specifying an initialization parameter or command-line options to the RECOVER command. The Oracle Server can use one process to sequentially read the log files and dispatch redo information to several recovery processes to apply the changes from the log files to the datafiles. The recovery processes are started automatically by Oracle, so there is no need to use more than one session to perform recovery.
What Situations Benefit from Parallel Recovery
In general, parallel recovery is most effective at reducing recovery time when several datafiles on several different disks are being recovered concurrently. Crash recovery (recovery after instance failure) and media recovery of many datafiles on many different disk drives are good candidates for parallel recovery.
Additional Information: The performance improvement from parallel recovery is also dependent upon whether the operating system supports asynchronous I/O. If asynchronous I/O is not supported, parallel recovery can dramatically reduce recovery time. If asynchronous I/O is supported, the recovery time may only be slightly reduced by using parallel recovery. Consult your operating system documentation to determine whether asynchronous I/O is supported on your system.
Recovery Processes
In a typical parallel recovery situation, one process is responsible for reading and dispatching redo entries from the redo log files. This is the dedicated server process that begins the recovery session, typically a Server Manager session or an application designed to use the ALTER DATABASE RECOVER ... command. The server process reading the redo log files enlists two or more recovery processes to apply the changes from the redo entries to the datafiles. Figure 24 - 2 illustrates a typical parallel recovery session.

Figure 24 - 2. Typical Parallel Recovery Session
In most situations, one recovery session and one or two recovery processes per disk drive containing datafiles needing recovery is sufficient. Recovery is a disk-intensive activity as opposed to a CPU-intensive activity, and therefore the number of recovery processes needed is dependent entirely upon how many disk drives are involved in recovery. In general, a minimum of eight recovery processes is needed before parallel recovery can show improvement over a serial recovery.
Recovery from Instance Failure
When an instance is aborted, either unexpectedly (for example, an unexpected power outage or a background process failure) or expectedly (for example, when you issue a SHUTDOWN ABORT or STARTUP FORCE statement), instance failure occurs, and instance recovery is required. Instance recovery restores a database to its transaction-consistent state just before instance failure.
If you experience instance failure during online backup, media recovery might be required. In all other cases, Oracle automatically performs instance recovery for a database when the database is restarted (mounted and opened to a new instance). If necessary, the transition from a mounted state to an open state automatically triggers instance recovery, which consists of the following steps:
1. Rolling forward to recover data that has not been recorded in the datafiles, yet has been recorded in the online redo log, including the contents of rollback segments.
2. Opening the database. Instead of waiting for all transactions to be rolled back before making the database available, Oracle enables the database to be opened as soon as cache recovery is complete. Any data that is not locked by unrecovered transactions is immediately available. This feature is called fast warmstart.
3. Marking all transactions system-wide that were active at the time of failure as DEAD and marking the rollback segments containing these transactions as PARTIALLY AVAILABLE.
4. Recovering dead transactions as part of SMON recovery.
5. Resolving any pending distributed transactions undergoing a two-phase commit at the time of the instance failure.
Read-Only Tablespaces and Instance Recovery
No recovery is ever needed on read-only datafiles after instance recovery. Recovery during startup verifies that an online read-only file does not need any media recovery. That is, the file was not restored from a backup taken before it was made read-only. If you restore a read-only tablespace from a backup taken before the tablespace was made read-only, you cannot access the tablespace until you complete media recovery.
Recovery from Media Failure
Media failure is a failure that occurs when a file, portion of a file, or a disk either cannot be read from or cannot be written to because it is damaged or missing. For example, this can happen if one or more datafiles are erased accidentally or lost due to a disk head crash.
Recovery from a media failure can take two forms, depending on the archiving mode in which the database is operated:
Recovery from a media failure, no matter what form, always recovers the entire database to a transaction-consistent state before the media failure. It is not logical or possible to recover a part of a database (such as a tablespace) to one point in time, and recover (or leave untouched) another part of a database to a different point in time; otherwise, the database would not be in a transaction-consistent state with respect to itself.
The following sections describe the different types of media recovery available if a database is operated in ARCHIVELOG mode: complete media recovery and incomplete media recovery.
Read-Only Tablespaces and Media Recovery
Normal media recovery does not check the read-only status of a datafile. When you perform media recovery of a tablespace that was once read-only, you have three possible options, depending upon when the tablespace was made read-only and when you performed the most recent backup. These scenarios are illustrated in Figure 24 - 3.
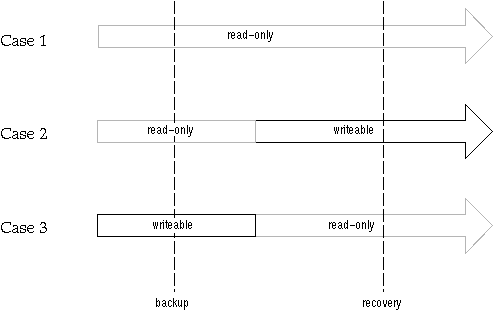
Figure 24 - 3. Type of Media Recovery
Case 1 The tablespace being recovered is read-only, and was read-only when the last backup occurred. In this case, you can simply restore the tablespace from the backup. There is no need to apply any redo information.
Case 2
The tablespace being recovered is writeable, but was read-only when the last backup occurred. In this case, you would need to restore the tablespace from the backup and apply the redo information from the point of time when the tablespace was made writeable.
Case 3
The tablespace being recovered is read-only, but was writeable when the last backup occurred. Because you should always backup a tablespace after making it read-only, you should not experience this situation. However, if this does occur, you must restore the tablespace from the backup and recover up to the time that the tablespace was made read-only.
Unlike writeable datafiles, read-only datafiles are not taken offline automatically if a media failure occurs. If you experience a media failure that affects only a portion of your datafiles, you should take these datafiles offline and follow the instructions in the Oracle7 Server Administrator's Guide for performing recovery of offline tablespaces in an open database.
Complete Media Recovery
Complete media recovery recovers all lost changes; no work is lost. Complete media recovery is possible only if all necessary redo logs (online and archived) are available.
Different types of complete media recovery are available, depending on the files that are damaged and the availability of the database that is required during recovery operations.
Closed Database Recovery
Complete media recovery of all or individual damaged datafiles can proceed while a database is mounted but closed and completely unavailable for normal use. Closed database recovery is used in the following situations:
- The database does not have to be open (in other words, the undamaged portions of the database do not have to be available for use).
- Files damaged by the disk failure include one or more datafiles that constitute the SYSTEM tablespace or a tablespace containing active rollback segments.
Open Database-Offline Tablespace Recovery
Complete media recovery can proceed while a database is open. Undamaged tablespaces of the database are online and available for use, while a damaged tablespace is offline, and all datafiles that constitute the damaged tablespace are recovered as a unit. Offline tablespace recovery is used in the following situations:
- Undamaged tablespaces of the database must be available for normal use.
- Files damaged by the disk failure do not include any datafiles that constitute the SYSTEM tablespace or a tablespace containing active rollback segments.
Open Database-Offline Tablespace-Individual Datafile Recovery
Complete media recovery can proceed while a database is open. Undamaged tablespaces of the database are online and available for use, while a damaged tablespace is offline and specific damaged datafiles associated with the damaged tablespace are recovered. Individual datafile recovery is used in the following situations:
- Undamaged tablespaces of the database must be available for normal use.
- Files damaged by the disk failure do not include any datafiles that constitute the SYSTEM tablespace or a tablespace containing active rollback segments.
Complete Media Recovery Using a Backup of the Control File
Complete media recovery can proceed without loss of data, even if all copies of the control file are damaged by a disk failure. Media recovery of datafile backups can be done even if the control file is a backup. The control file is not recovered by media recovery; rather the RESETLOGS at database open recovers the control file.
The Mechanisms of Complete Media Recovery
The mechanisms that Oracle uses to perform any type of complete media recovery are best described using an example. The following is an example of complete media recovery of damaged datafiles while the database is open and a damaged tablespace is offline. Assume the following:
- the database has three datafiles:
- USERS1 and USERS2 are datafiles that constitute the USERS tablespace, stored on Disk X of the database server
- SYSTEM is the datafile that constitutes the SYSTEM tablespace, stored on Disk Y of the database server
- Disk X of the database server has crashed
- the online redo log file being written to at the time of the disk failure has a log sequence number of 31
- the database is in ARCHIVELOG mode
Recovery of the two datafiles that constitute the USERS tablespace is necessary because Disk X has been damaged, and the system has automatically taken the tablespace offline. In this case, the datafile of the SYSTEM tablespace is not damaged. Therefore, the database can be open with the SYSTEM tablespace online and available for use while recovery is completed on the offline tablespace needing recovery (USERS).
The following sections describe the phases of complete media recovery.
Phase 1: Restoration of Backup Datafiles After Disk X has been repaired, the most recent backup files are used to restore only the damaged datafiles USERS1 and USERS2. After restoration, the datafiles of the database exist as illustrated in Figure 24 - 4.
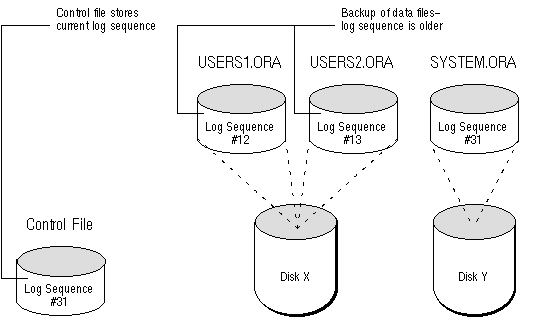 Figure 24 - 4. Phase 1 of Complete Media Recovery
Figure 24 - 4. Phase 1 of Complete Media Recovery
Each datafile header contains the most recent log sequence number being written at the time the datafile was being written. The restored backup files will have earlier log sequence numbers than those of the datafiles that were not affected (not restored) by the disk crash. The control file contains a pointer to the last log sequence number that was written.
Phase 2: Rolling Forward with the Redo Log As complete media recovery proceeds, Oracle applies redo log files (archived and online) to datafiles, as necessary, as illustrated in Figure 24 - 5. Oracle automatically detects when a redo log file does not contain any redo information corresponding to a restored backup datafile. Therefore, Oracle optimizes the recovery process by not attempting to apply the redo log file to the restored datafile.
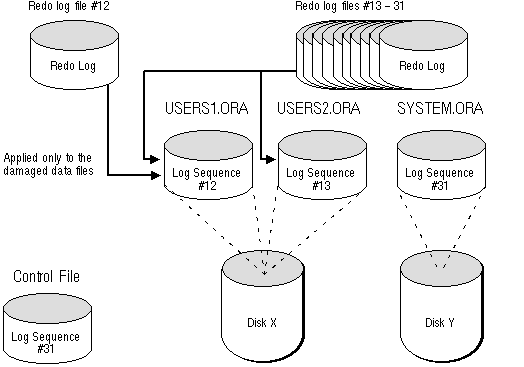
Figure 24 - 5. Phase 2 of Complete Media Recovery
In this case, the redo log file with the log sequence number of 12 is applied exclusively to USERS1, and the redo log files with log sequence numbers ranging from 13 to 31 are applied to both USERS1 and USERS2. No redo log files are applied to the datafiles that do not require recovery.
There is a flag in the header of the current redo log that indicates if it is the last available redo log file to apply to the restored datafiles.
Phase 3: Rolling Back Using Rollback Segments Once the necessary redo log files have been applied to the damaged datafiles, all uncommitted data that exists as a result of the roll forward in Phase 2 must be removed. This is completed by applying the deferred rollback segment as the tablespace is brought online, as illustrated in Figure 24 - 6.
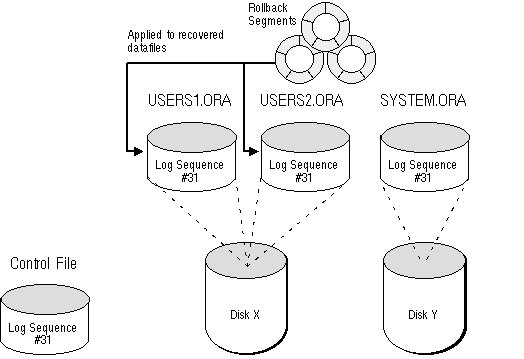
Figure 24 - 6. Phase 3 of Complete Media Recovery
After Phase 3 is complete, notice how the log sequence number contained in the datafile headers of the previously damaged and restored datafiles, USERS1 and USERS2, has been updated during Phase 2 of the recovery process. The USERS tablespace can now be brought online. Deferred rollback segments are applied to the files of the offline tablespace as it is brought back online. Once the rollback is complete, the datafiles USERS1 and USERS2 exist as they did at the instant before the disk failure. Once this is complete, all data in the tablespace is now consistent and available for use.
Incomplete Media Recovery
In specific situations (for example, the loss of all active online redo log files, or a user error, such as the accidental dropping of an important table), complete media recovery may not be possible or may not be desired. In such situations, incomplete media recovery is performed to reconstruct the damaged database to a transaction consistent state before the media failure or user error.
In most cases, unless desired, incomplete media recovery is not necessary if the online redo log has been mirrored to protect against having a single point of failure.
There are different types of incomplete media recovery that might be used, depending on the situation that requires incomplete media recovery: cancel-based, time-based, and change-based incomplete recovery.
Cancel-Based Recovery
In certain situations, incomplete media recovery must be controlled so that the administrator can cancel the operation at a specific point. Specifically, cancel-based recovery is used when one or more redo log groups (online or archived) have been damaged by a media failure and are not available for required recovery procedures (for example, the online redo log is not mirrored, and the single active online redo log file has been damaged by a disk failure). If one or more redo log groups are not available, the missing redo log groups cannot be applied during recovery procedures. Therefore, media recovery must be controlled so the recovery operation is terminated after the most recent, undamaged redo log group has been applied to the datafiles.
Time-Based and Change-Based Recovery
Incomplete media recovery is desirable if the database administrator would like to recover to a specific point in the past. This might be useful in the following situations:
- A user accidentally dropped a table and noticed the approximate time that the error was committed. The database administrator can immediately shut down the database and recover it to a point in time just before the user error.
- Part of an online redo log file (of a non-mirrored online redo log) might become corrupt due to a system failure. Therefore, the active online redo log file is suddenly unavailable, the database instance is aborted, and media recovery is now required. The redo entries in the most recently used online redo log file are valid up to the place that the corrupt data was written; later entries are invalid. Only the undamaged part of the current online redo log file can be applied. In this case, the database administrator can use time-based recovery to stop the recovery procedure once the valid portion of the most recent online redo log file has been applied to the datafiles.
In both of these cases, the endpoint of incomplete media recovery can be specified by a point in time or a specific system change number (SCN). An SCN is recorded in the redo log, along with the redo entries, each time that a transaction is committed. If a time is given, the database is recovered to the transaction consistent state just before the specified time. If an SCN is given, the database is recovered to the transaction committed just before the specified SCN.
The Mechanisms of Incomplete Database Recovery
Incomplete database recovery proceeds in the same way as complete media recovery, with a few exceptions:
- All datafiles must be restored using backup files completed before the intended point of recovery (the files could even come from different partial backups taken at different times). This way, the entire database is taken to a point in time before the recovery point and rolled forward to the intended point of recovery.
- For best results, the control file used during incomplete media recovery should reflect the physical structure of the database for the intended time of recovery. If you open the database using the RESETLOGS option, or if you open the database after issuing a CREATE CONTROLFILE statement, Oracle cross-checks the control file with the current data dictionary. If any datafiles have been added to, or dropped from, the data dictionary, Oracle updates the control file accordingly. Any other differences are reported with error messages.
- Recovery might terminate before all the available redo logs are applied. The recovery operation can be canceled manually, or it will be terminated automatically when the stop point is reached.
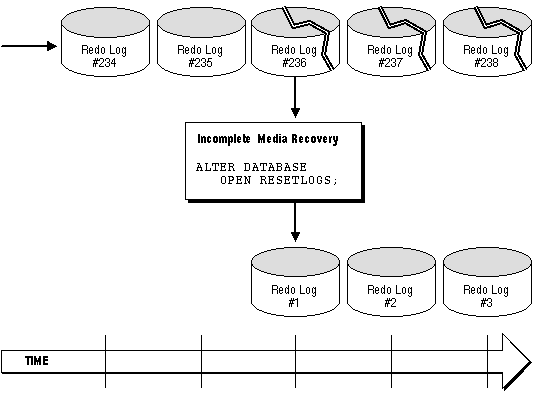
Figure 24 - 7. Effects of Resetting the Log Sequence Number after Incomplete Media Recovery