| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
![]()
![]()
Aeschylus, Antigone
This chapter provides an overview of tuning issues. It covers the following topics:
In tuning OPS applications the techniques used for single-instance applications are still valid. It is still important, however, to effectively tune the buffer cache, shared pool and all the disk subsystems. OPS introduces some additional parameters and statistics that you must must collect and understand.
When collecting statistics to monitor the performance of the OPS, the following general guidelines will make debugging and monitoring of the system simpler and more accurate.
On an MPP machine, when multiple instances are to be started, start node 1 first, to allow that single node to open all the locks and perform instance recovery, if necessary. Afterwards, the other instances can be started simultaneously.
See Also: "Lock Mastering" ![[*]](jump.gif) .
.
To determine the number of lock converts over a period of time, query the V$LOCK_ACTIVITY table. From this you should be able to determine whether you have reached the maximum lock convert rate for the DLM. If this is the case, you must repartition the application to remove the bottleneck. In this situation, adding more hardware resources such as CPUs, disk drives, and memory is unlikely to improve system performance significantly.
Note: Maximum lock convert rate varies from one distributed lock manager to another. Please check your DLM vendor's operating system documentation to ascertain this value.
To determine whether lock converts are being performed too often, calculate how often the transaction requires a lock convert operation when a data block is accessed for either a read or a modification. Query the V$SYSSTAT table.
In this way you can calculate a lock hit ratio which may be compared to the cache hit ratio. The value calculated is the number of times there occur data block accesses that do not require lock converts, compared to the total number of data block accesses. The lock hit ratio is computed as
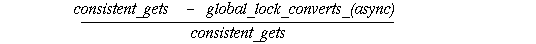 A SQL statement that computes this ratio is as follows:
A SQL statement that computes this ratio is as follows:
SELECT (b1.value - b2.value) / b1.value ops_ratio
FROM V$SYSSTAT b1, V$SYSSTAT b2
WHERE b1.name = `consistent gets'
AND b2.name = `global lock converts (async)';
If this ratio drops below 95%, optimal scaling of performance may not be achieved as additional nodes are added.
Another indication of too many PCM lock conversions is the ping/write ratio, which is determined as follows:
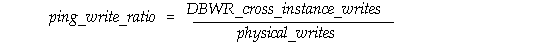 See Also: "Tuning Your PCM Locks" .
See Also: "Tuning Your PCM Locks" .
In some cases within OPS applications the system may not be performing as anticipated. This may be because one small area of the database setup or application design overlooked some database blocks that must be accessed in exclusive mode by all instances, for the entire time that the application runs. This forces the whole system to effectively single thread with respect to this resource.
This problem can also occur in single instance cases where all users require exclusive access to a single resource. In an inventory system, for example, all users may wish to modify a common stock level.
In OPS applications the most common points for contention are associated with contention for a common set of database blocks. To determine whether this is happening you can query an additional set of V$ tables (V$BH, V$CACHE and V$PING). All these tables yield basically the same data, but V$CACHE and V$PING have been created as views joining additional data dictionary tables to make them easier to use. These tables and views examine the status of the current data blocks within an instance's SGA. They enable you to construct queries to see how many times a block has been pinged between nodes, and how many revisions of the same data block exist within the SGA at the same time. You can use both of these features to determine whether excessive single threading upon a single database block is occurring.
The most common areas of high block contention tend to be:
If, however, many of the lock converts can be satisfied by just converting the lock without a disk I/O, a performance improvement can be made. This is often referred to as an I/O less ping. The reason that the lock convert can be achieved without an I/O is that the database is able to age the data blocks out of the SGA via the database writer, as it would with a single instance. This is only likely when the table is very large in comparison to the size of the SGA. Small tables are likely to require a disk I/O, since they are unlikely to be aged out of the SGA.
With small tables where random access occurs you can still achieve performance improvements by reducing the number of rows stored in a data block. You can do this by increasing the table PCTFREE value and by reducing the number of data blocks managed by a PCM lock. The process of adjusting the number of rows managed per PCM lock can be performed until lock converts are minimized or the hardware configuration runs out of PCM locks.
The number of PCM locks managed by the DLM is not an infinite resource. Each lock requires memory on each OPS node, and this resource may be quickly be exhausted. Within an OPS environment the addition of more PCM locks lengthens the time taken to restart or recover an OPS instance. In environments where high availability is required, the time taken to restart or recover an instance may determine the maximum number of PCM locks that you can practically allocate.
Where random access is taking place, lock converts are performed even if there is not contention for the same data block. In this situation tuning the number of locks is unlikely to enhance performance, since the number of locks required is far in excess of what can actually be created by the lock manager.
In such cases you must either restrict access to these database objects or else develop a partitioned solution.
See Also: "Phases of DLM and Oracle Recovery" .
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |