| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
![]()
![]()
After instance failure, Oracle uses the online redo log files to perform automatic recovery of the database. For a single instance running in exclusive mode, instance recovery occurs as soon as the instance starts up again after it has failed or shut down abnormally, as described in the "Recovering a Database" chapter of Oracle7 Server Administrator's Guide.
When instances accessing the database in shared mode fail, online instance recovery is performed automatically. Instances that continue running on other nodes are not affected, as long as they are reading from the buffer cache. If instances attempt to write, the transaction will stop. All operations to the database are suspended until cache recovery of the failed instance is complete.
Online instance recovery does not include restarting the failed instance or any applications that were running on that instance.
When one instance performs recovery for another instance that has failed, the surviving instance reads the redo log entries generated by the failed instance, and uses that information to ensure that all committed transactions are reflected in the database. No data from committed transactions is lost.
The instance that is performing recovery rolls back any transactions that were active at the time of the failure and releases any resources being used by those transactions.
If all instances of a parallel server fail, instance recovery is performed automatically the next time an instance opens the database. The instance does not have to be one of the instances that failed, and it can mount the database in either shared or exclusive mode from any node of the parallel server. This recovery procedure is the same for Oracle running in shared mode as it is for Oracle in exclusive mode, except that one instance performs instance recovery for all of the instances that failed.
After you correct the problem that prevented access to the database files, you must use the SQL statement ALTER SYSTEM CHECK DATAFILES to make the files available to the instance.
See Also: "Datafiles" ![[*]](jump.gif) .
.
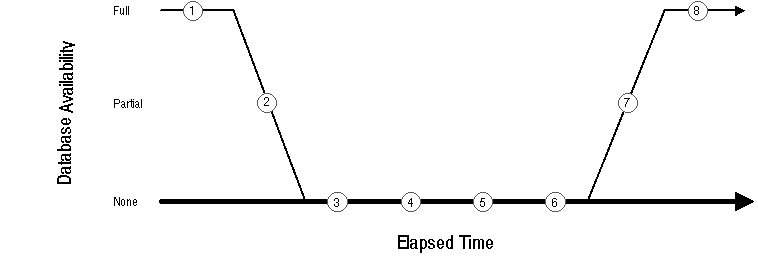 Figure 23 - 1. Phases of DLM and Oracle Recovery
Figure 23 - 1. Phases of DLM and Oracle Recovery
Phases of recovery are these:
The transitional state of the buffer cache begins at the conclusion of the initial lock scan phase when instance recovery is first started by scanning for dead redo threads. Subsequent lock scans are made if new dead threads are discovered. This state lasts while the redo log is applied (cache recovery) and ends when the redo logs have been applied and the file headers have been updated. Cache recovery operations conclude with validation of the invalid locks, which occurs after the buffer cache state is normalized.
See Also: "Recovering a Database" in the Oracle7 Server Administrator's Guide for recovery procedures for various kinds of media failure.
| To Recover | Database Status |
| An entire database or the SYSTEM tablespace | The database must be mounted but not opened by any instance. |
| A tablespace other than the SYSTEM tablespace | The database must be opened by the instance performing the recovery and the tablespace must be offline. |
| A datafile | The database can be open with the datafile offline, or the database can be mounted but not opened by any instance. (For a datafile in the SYSTEM tablespace, the database must be mounted but not open.) |
You can use the Server Manager Recover dialog box with the Database radio button, or the RECOVER DATABASE command to recover a database that is mounted in shared mode, but not open. Only one instance can issue this command in a parallel server.
To perform online recovery of tablespaces or datafiles in shared mode, you can use either the Server Manager Recover dialog box with the Tablespace or Datafile radio button or the command RECOVER TABLESPACE or RECOVER DATAFILE.
You can recover multiple datafiles or tablespaces on multiple instances simultaneously.
Note: The recommended method of recovering a database is to use Server Manager. Direct use of the ALTER DATABASE RECOVER SQL command is not recommended.
However, if a thread's online redo log contains enough recovery information, mounting any archived log files for that thread will be unnecessary.
When recovering using Server Manager, you are prompted for the archived log files as they are needed. Messages supply information about the required files, and Server Manager prompts you for the filename.
For example, if the log history is enabled and the filename format is LOG_T%t_SEQ%s, where %t is the thread and %s is the log sequence number, then you might receive these messages to begin recovery with SCN 9523 in thread 8:
ORA-00279: Change 9523 generated at 27/09/91 11:42:54 needed for thread 8
ORA-00289: Suggestion : LOG_T8_SEQ438
ORA-00280: Change 9523 for thread 8 is in sequence 438
Specify log: {<RET> = suggested | filename | AUTO | FROM | CANCEL} If you use the ALTER DATABASE command with the RECOVER clause instead of Server Manager, you receive these messages but not the prompt. Redo log files may be required for each enabled thread in the parallel server. When a log file is no longer needed, Oracle issues a message indicating that you can dismount the file. The next log file for that thread is then requested, unless the thread was disabled or recovery is finished.
If recovery reaches a time when an additional thread was enabled, Oracle simply requests the archived log file for that thread. Whenever an instance enables a thread, it writes a redo entry that records the change; therefore, all necessary information about threads is available from the redo log files during recovery.
If recovery reaches a time when a thread was disabled, Oracle informs you that the log file for that thread is no longer needed and does not request any further log files for the thread.
Note: If Oracle reconstructs the names of archived redo log files, the format that LOG_ARCHIVE_FORMAT specifies for the instance doing recovery must be the same as the format specified for the instances that archived the files. All instances should use the same value of LOG_ARCHIVE_FORMAT in a parallel server, and the instance performing recovery should also use that value. You can specify a different value of LOG_ARCHIVE_DEST during recovery if the archived redo log files are not at their original archive destinations.
To Perform Disaster Recovery in OPS
RECOVER DATABASE USING BACKUP CONTROLFILE UNTIL CANCEL
You can parallelize instance and media recovery in two ways:
The Oracle Server can use one process to read the log files sequentially and dispatch redo information to several recovery processes to apply the changes from the log files to the datafiles. The recovery processes are started automatically by Oracle, so there is no need to use more than one session to perform recovery.
See Also: Your Oracle system-specific documentation for more information on the allocation of recovery processes to instances.
Oracle7 Server Concepts for more information on parallel recovery.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |