| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
![]()
![]()
This chapter covers the following topics:
See Also: "Allocating PCM Instance Locks" ![[*]](jump.gif) for details on how to plan and assign these locks.
for details on how to plan and assign these locks.
Figure 9 - 1 highlights PCM locks in relation to other locks used in Oracle.
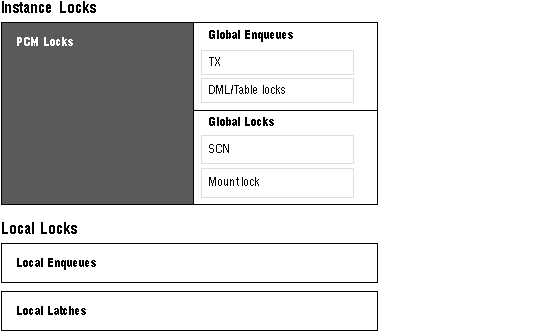 Figure 9 - 1. Oracle Locking Mechanisms: PCM Locks
Figure 9 - 1. Oracle Locking Mechanisms: PCM Locks
PCM locks use the minimum amount of communication to ensure cache coherency. The amount of cross-instance activity--and the corresponding performance of a parallel server--is evaluated in terms of pings. A ping occurs each time a block must be written to disk by one instance so that another instance can read it.
Note that busy systems can have a great deal of locking activity, but do not necessarily have pinging. If data is well partitioned, then the locking will be local to each node--therefore pinging will not occur.
You use the initialization parameter GC_FILES_TO_LOCKS to specify the number of PCM locks which cover the data blocks in a data file or set of data files. The smallest granularity is one PCM lock per datablock. Typically, a PCM lock covers a number of datablocks. PCM locks usually account for the greatest proportion of instance locks in a parallel server.
The first instance that starts up will initialize the lock value block for each DLM resource. The lock value block is an area in each DLM resource where lock history information can be stored. When an instance obtains a lock on the resource in exclusive mode, it owns the lock value block and can store information in it. The lock value block is read, for example, when converting a lock from null to exclusive; after an operation is performed and the lock is converted from exclusive to null mode, the lock value block is written.
Fine grain locking (also known as DBA locking) is more dynamic than hashed locking. For example, if you set GC_RELEASABLE_LOCKS to 10000 you can obtain up to ten thousand fine grain PCM locks. However, locks are allocated only as needed by the DLM. At startup Oracle allocates lock elements, which are obtained directly in the requested mode (normally shared or exclusive mode).
Figure 9 - 2 illustrates the way PCM locks work. When instance A reads in the black block for modifications, it obtains the PCM lock for the black block. The same scenario occurs with the shaded block and Instance B. If instance B requires the black block, the block must be written to disk because instance A has modified it. The ORACLE process communicates with the LCK process in order to obtain the lock from the DLM.
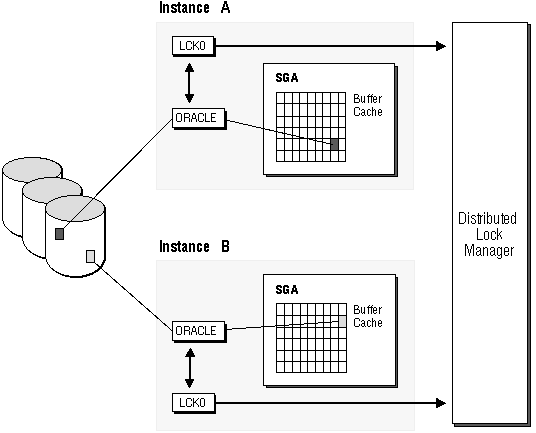 Figure 9 - 2. How PCM Locks Work
Figure 9 - 2. How PCM Locks Work
LCK processes maintain PCM locks on behalf of the instance. The LCK processes obtain and convert hashed PCM locks; they obtain, convert, and release fine grained PCM locks.
The number of hashed PCM locks assigned to datafiles and the number of data blocks in those datafiles determines the number of data blocks covered by a single PCM lock.
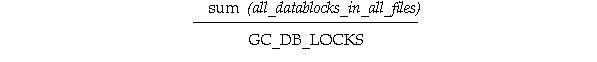
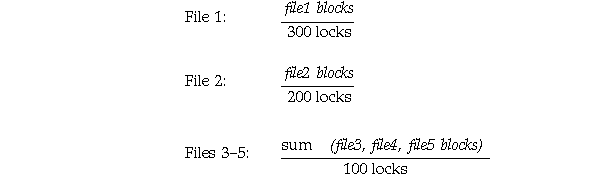
If the size of each file, in blocks, is a multiple of the number of PCM locks assigned to it, then each hashed PCM lock covers exactly the number of data blocks given by the equation.
If the file size is not a multiple of the number of PCM locks, then the number of data blocks per hashed PCM lock can vary by one for that datafile. For example, if you assign 400 PCM locks to a datafile which contains 2,500 data blocks, then 100 PCM locks cover 7 data blocks each and 300 PCM locks cover 6 blocks. Any datafiles not specified in the GC_FILES_TO_LOCKS initialization parameter use the remaining PCM locks. The number of remaining PCM locks equals the value of GC_DB_LOCKS less the sum of all #locks values specified in GC_FILES_TO_LOCKS.
If n files share the same hashed PCM locks, then the number of blocks per lock can vary by as much as n. If you assign locks to individual files, either with separate clauses of GC_FILES_TO_LOCKS or by using the keyword EACH, then the number of blocks per lock does not vary by more than one.
If you assign hashed PCM locks to a set of datafiles collectively, then each lock usually covers one or more blocks in each file. Exceptions can occur when you specify contiguous blocks (using the "!blocks" option) or when a file contains fewer blocks than the number of locks assigned to the set of files.
Attention: One lock is always reserved for database additions. Thus, if all but one lock are already distributed explicitly to existing files, and new files are added to the database, it is possible that entire files may end up sharing a single lock. To avoid such situations, carefully examine GC_* parameter values when adding files.
Block 1 of a file does not necessarily begin with lock 1; a hashing function determines which lock a file begins with. In file A, which has 24 blocks, block 1 hashes to lock 32. In file B, which has 20 blocks, block 1 hashes to lock 28.
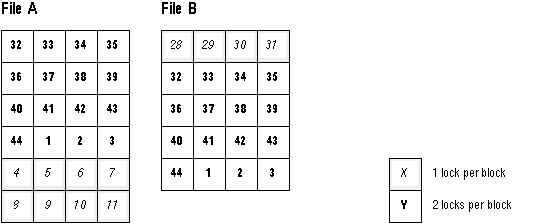 Figure 9 - 3. Hashed PCM Locks Covering Blocks in Multiple Files
Figure 9 - 3. Hashed PCM Locks Covering Blocks in Multiple Files
In Figure 9 - 3, locks 32 through 44 and 1 through 3 are used to cover 2 blocks each. Locks 4 through 11 and 28 through 31 cover 1 block each; and locks 12 through 27 cover no blocks at all!
In a worst case scenario, if two files hash to the same lock as a starting point, then all the common locks will cover two blocks each. If your files are large and have multiple blocks per lock (on the order of 100 blocks per lock), then this is not an important issue.
 Figure 9 - 4. Periodicity of Hashed PCM Locks
Figure 9 - 4. Periodicity of Hashed PCM Locks
Note that data blocks are pinged only when a block that is held in the exclusive current (XCUR) state in the buffer cache of one instance, is needed by a different instance. In some cases, therefore, the number of PCM locks covering data blocks may have little impact on whether a block gets pinged. You can have lost a PCM lock on a block and still have a row lock on it: pinging is independent of whether a commit has occurred. You can modify a block, but whether or not it is pinged is independent of whether you have made the commit.
If you have partitioned data across instances and are doing updates, you can have a million blocks each on the different instances, and still not have any pinging. As shown in Figure 9 - 5, if a single PCM lock covers one million data blocks in a table which are read/write into the SGA of instance X, and another single PCM lock covers another million data blocks in the table which are read/write into the SGA of instance Y, then regardless of the number of updates, no data blocks will ever ping between instance X and instance Y.
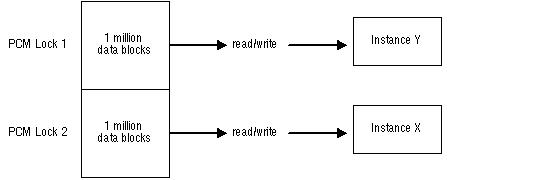 Figure 9 - 5. Partitioning Data to Avoid Pinging
Figure 9 - 5. Partitioning Data to Avoid Pinging
With read-only data, both instance X and instance Y can hold the PCM lock in shared mode, and no pinging will take place. This scenario is illustrated in Figure 9 - 6.
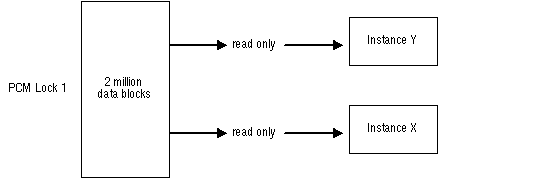 Figure 9 - 6. No Pinging of Read-only Data
Figure 9 - 6. No Pinging of Read-only Data
| PCM Lock Mode | Buffer State Name | Description |
| X | XCUR | Instance has an EXCLUSIVE lock for this buffer |
| S | SCUR | Instance has a SHARED lock for this buffer |
| N | CR | Instance has a NULL lock for this buffer |
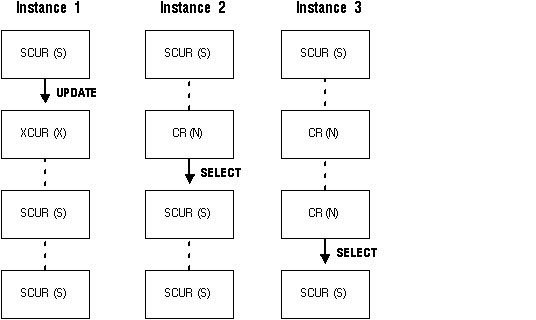 Figure 9 - 7. How State of Buffer and Lock Mode Change
Figure 9 - 7. How State of Buffer and Lock Mode Change
In Figure 9 - 7 the three instances start out with blocks in shared current mode, and shared locks. When Instance 1 performs an update on the block, its lock mode on the block changes to exclusive mode (X). The shared locks owned by Instance 2 and Instance 3 convert to null mode (N). Meanwhile, the block state in Instance 1 becomes XCUR, and in Instance 2 and Instance 3 becomes CR. These lock modes are compatible. Similar conversions of lock mode and block state occur when Instance 2 performs a SELECT operation on the block, and when Instance 3 performs a SELECT operation on it.
Note: The DLM concurrent read mode (CR) should not be confused with the consistent read buffer state (also abbreviated as CR).
| Lock Requested: Lock Owned | Null | SS | SX | S | SSX | X |
| NULL | SUCCEED | SUCCEED | SUCCEED | SUCCEED | SUCCEED | SUCCEED |
| SS | SUCCEED | SUCCEED | SUCCEED | SUCCEED | SUCCEED | FAIL |
| SX | SUCCEED | SUCCEED | SUCCEED | FAIL | FAIL | FAIL |
| S | SUCCEED | SUCCEED | FAIL | SUCCEED | FAIL | FAIL |
| SSX | SUCCEED | SUCCEED | FAIL | FAIL | FAIL | FAIL |
| X | SUCCEED | FAIL | FAIL | FAIL | FAIL | FAIL |
| Parameter | Description | Value |
| GC_DB_LOCKS | Sets maximum number of PCM locks for all datafiles. Some of these are hashed locks specified by the GC_FILES_TO_ LOCKS parameter. The remaining locks form a pool of hashed locks to protect database blocks which are not explicitly mentioned in the GC_FILES_TO_LOCKS parameter. | If GC_DB_LOCKS is set to zero, then GC_FILES_TO_LOCKS is ignored and all data blocks (class 1) use fine grain locks.
GC_DB_LOCKS must be set to
the same value on all instances. It
defaults to the value of DB_BLOCK_BUFFERS. Note: The value of DB_BLOCK_ BUFFERS, however, does not need to be identical on all instances. If you explicitly set GC_DB_LOCKS to the same value on all instances, then the value of DB_BLOCK_BUFFERS can vary from instance to instance. |
| GC_FILES_TO_LOCKS | Gives the mapping of hashed locks (GC_DB_LOCKS) to blocks within each datafile. The meaning of this parameter has changed. Previously, files not mentioned in this parameter (or files added later) were assigned the remaining hashed locks. You can now have multiple entries of GC_FILES_TO_LOCKS. | The configuration string for GC_FILES_TO_LOCKS now includes a value of zero for the number of locks. This indicates that the blocks are protected by fine grain locks. Instances must have identical values. |
| GC_FREELIST_GROUPS | Determines the number of locks to specify for free list group blocks. | Default is 5 times the value of GC_SEGMENTS. Instances must have identical values. |
| GC_LCK_PROCS | Sets the number of background lock processes (LCK0 through LCK9) for an instance in a parallel server. | In shared mode, the value of this parameter must be greater than 1; the default value is 1. In exclusive mode, this parameter is ignored. Instances must have identical values. |
| GC_RELEASABLE_LOCKS | Sets the maximum number of releasable locks in an instance. If persistent locking is supported by platform and DLM, these blocks will be allocated for releasable locks (as needed). If any other GC parameters contain a zero value, or if in GC_FILES_TO_ LOCKS you assign zero locks to a specific file number, then the GC_RELEASABLE_LOCKS parameter will be used to allocate releasable locks for those block classes or files. If, however, you do not explicitly set zero for any other GC parameters, or for a specific file, then this parameter is ignored. It does not affect the default locking mode. Support of fine grain locking is platform-specific. | Defaults to the value of DB_BLOCK_BUFFERS, if releasable (fine grain) locks are being used. Larger values may be advantageous. No maximum value exists, except as imposed by space restrictions, or by the maximum number of locks which a single process can hold. This parameter will default to zero if releasable locks are not being used. Each instance can have a different number of releasable locks. If you want each block class to be releasable, you must set the corresponding parameter to zero. See Table 9 - 4. |
| GC_ROLLBACK_LOCKS | For each rollback segment, specifies the number of instance locks available for simultaneously modified rollback segment blocks. | The default value is 20. A value of zero causes fine grain locking to be used. Instances must have identical values. |
| GC_ROLLBACK_SEGMENTS | Specifies the maximum number of rollback segments system-wide, hence the number of hashed locks for undo segment headers (transaction tables). Hashed (non-releasable) locks are always used because no conflict between segment headers is possible. | Default value is 20. A value of zero causes fine grain locking to be used. Instances must have identical values. |
| GC_SAVE_ROLLBACK_LOCKS | Reserves instance locks for deferred rollback segments, which contain rollback entries for transactions in tablespaces which have been taken offline | Default value is 20. A value of zero causes fine grain locking to be used. Instances must have identical values. |
| GC_SEGMENTS | Specifies number of hashed locks to create for the segment header class of blocks. | Default value is 10. A value of zero causes fine grain locking to be used. Instances must have identical values. |
| GC_TABLESPACES | Sets the maximum number of offline tablespaces which can contain outstanding transactions (see GC_SAVE_ROLLBACK_LOCKS) | Default value is 5. A value of zero causes fine grain locking to be used. Instances must have identical values. |
See Also: "Initialization Parameters" for complete specifications for these initialization parameters.
"Allocating PCM Locks" chapter provides information on how to set these parameters.
Each of the initialization parameters protects a different class of blocks. Database blocks belonging to an object will have at least two different classes: segment header class and data class. For each object there will be only one segment header block and the other blocks will be of class 1 data. As of Oracle Parallel Server release 7.3, if you have unlimited extents in a table you will have an additional class 6 block for extended segment headers.
Table 9 - 4 shows the GC_* parameters you can use to make different block classes releasable.
| Class | Description | How to Make Class Releasable |
| 1 | Data or index blocks | GC_FILES_TO_LOCKS: use to set number of locks, so that you can specify which files are releasable. GC_DB_LOCKS=0: if set, all files are releasable. |
| 2 | Sort blocks | no PCM locks are used |
| 3 | Save undo blocks | GC_SAVE_ROLLBACK_LOCKS=0 |
| 4 | Segment headers | GC_SEGMENTS=0 |
| 5 | Save undo segment header blocks | GC_TABLESPACES=0 |
| 6 | Free list group blocks | GC_FREELIST_GROUPS=0 |
| 7 | System undo segment header blocks | releasable if any other class is releasable; otherwise, they are covered by a single lock |
| 8 | System undo segment blocks | GC_ROLLBACK_LOCKS=0 |
| 7 + (n * 2) | User undo segment n header block | releasable if any other class is releasable; otherwise, they are covered by a single lock |
| 7 +( (n * 2) + 1) | User undo segment n header block | GC_ROLLBACK_LOCKS=0 |
Note: In Table 9 - 4, n represents the rollback segment number: n = 0 indicates system rollback segment n > 0 indicates non-system rollback segment
If the GC_RELEASABLE_LOCKS initialization parameter is set, then you do not need to set corresponding GC_* parameters for the particular block classes you want to be releasable (fine grain) locks. You do need to set GC_* parameters if you want particular block classes to be hashed locks.
data blocks
These blocks contain data from indexes or tables.
sort blocks
These blocks contain data from on-disk sorts and internal temporary tables.
save undo blocks
This is also known as "deferred rollback segment". When you apply undo to an offline tablespace, the undo is stored in a deferred rollback segment. When the tablespace comes back online, the undo is automatically applied to the tablespace. Save undo blocks always reside in the system tablespace.
segment header blocks
The segment header block is the first block of a segment (table/index). It contains information about the segment and the extents in the segment.
save undo header blocks
These are header blocks for the "save undo" blocks.
free list blocks
Following the segment header is a block for each free list group specified in the storage clause of the CREATE TABLE or CREATE INDEX statement. Each block contains information on the freelists in that particular free list group.
(system) undo header blocks
These are also known as the rollback segment headers or transaction tables.
(system) undo blocks
These undo blocks are part of the rollback segment and provide storage for undo records.
SQL> SELECT CLASS#
FROM V$BH
 Figure 9 - 8. Blocks in a Sample Oracle Datafile
Figure 9 - 8. Blocks in a Sample Oracle Datafile
| Block | Contents | Protection |
| 0 | Operating system header | Not protected by PCM lock |
| 1 | Oracle file header | Not protected by PCM lock |
| 2 | Segment header | Protected by GC_SEGMENT |
| 3 | Freelist group 1 | Protected by GC_FREELIST_GROUPS |
| 4 | Freelist group 2 | Protected by GC_FREELIST_GROUPS |
| 5 | Data block | Protected by GC_DB_LOCKS and GC_FILES_TO_LOCKS |
| 6 | Data block | Protected by GC_DB_LOCKS and GC_FILES_TO_LOCKS |
| 7 | Data block | Protected by GC_DB_LOCKS and GC_FILES_TO_LOCKS |
| 8 | End of table | Protected by GC_DB_LOCKS and GC_FILES_TO_LOCKS |
| 9 | Rollback segment header | Protected by GC_ROLLBACK_SEGMENTS |
| 10 | Data block for rollback segment | Protected by GC_ROLLBACK_LOCKS |
| 11 | Data block for rollback segment | Protected by GC_ROLLBACK_LOCKS |
| 12 | Data block for rollback segment | Protected by GC_ROLLBACK_LOCKS |
| 13 | Data block for rollback segment | Protected by GC_ROLLBACK_LOCKS |
| 14 | Data block for rollback segment | Protected by GC_ROLLBACK_LOCKS |
| 15 | Data block for rollback segment | Protected by GC_ROLLBACK_LOCKS |
Classes of blocks, and the locks and parameters which affect them, imply some important guidelines for handling data blocks in your files
Segment header blocks, for example, are protected by GC_SEGMENTS. Freelist group blocks are controlled by GC_FREELIST_GROUP: the number of locks allocated for free list group blocks is equal to five times the value of GC_SEGMENTS, by default.
Do not allocate PCM locks for files which only contain the following, because class 1 blocks are not used for these files:
Fine grain locks are releasable: an instance can give up all references to the resource name during normal operation. The DLM resource is released when it is required for reuse for a different block. This means that sometimes no instance holds a lock on a given resource.
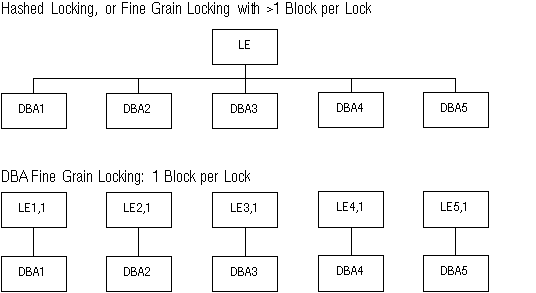 Figure 9 - 9. Hashed Locking and DBA Fine Grain Locking
Figure 9 - 9. Hashed Locking and DBA Fine Grain Locking
When the lock element is pinged, any other modified blocks owned by that lock element will be written along with the needed one. For example, in Figure 9 - 9, if LE is pinged when block DBA2 is needed, blocks DBA1, DBA3, DBA4, and DBA5 will all be written to disk as well--if they have been modified.
Although a fixed number of lock elements cover potentially millions of blocks, the lock element names change over and over again as they are associated with specific blocks that are requested. The lock element name (for example, LE7,1) contains the database block address (7) and class (1) of the block it covers. Before a lock element can be reused, the DLM lock must be released. You can then rename and reuse the lock element, creating a new resource in the DLM if necessary.
When using fine grain locking, you can set your system with many more potential lock names, since they do not need to be held concurrently. However, the number of blocks mapped to each lock is configurable in the same way as hashed locking.
Hashed locks are useful in the following situations:
| Situation | Reason |
| when the data is mostly read-only | A few hashed locks can cover many blocks without requiring frequent lock operations. These locks are released only when another instance needs to modify the data. Hashed locking can perform up to 100% faster than fine grain locking on read-only data with the Parallel Query Option. Note: If the data is strictly read-only, consider designating the tablespace itself as read-only. The tablespace will not then require any PCM locks. |
| when the data can be partitioned according to the instance which is likely to modify it | Hashed locks which are defined to match this partitioning allow instances to hold disjoint DLM lock sets, reducing the need for DLM operations. |
| when a large set of data is modified by a relatively small set of instances | Hashed locks permit access to a new database block to proceed without DLM activity, if the lock is already held by the requesting instance. |
Hashed locks may cause extra cross-instance lock activity, since conflicts may occur between instances which are modifying different database blocks. The resolution of this false conflict ("false pinging") may require writing several blocks from the cache of the instance which currently owns the lock.
On most systems an instance could not possibly hold a lock for each block of a database since SGA memory or DLM locking capabilities would be exceeded. Therefore, instances acquire and release fine grain locks as required. Since fine grain locks, lock elements, and resources are renamed in the DLM and reused, a system can employ fewer of them. The value of DB_BLOCK_BUFFERS is the minimum number of fine grain locks you can allocate.
DBA fine grain locks are useful when a database object is updated frequently by several instances. This advantage is gained as follows:
See Also: "Fine Grain Examples" .
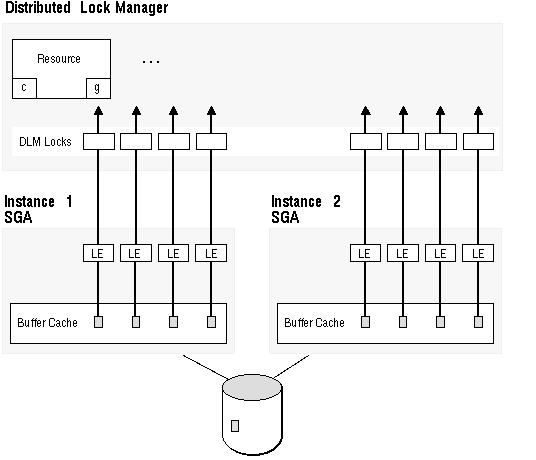 Figure 9 - 10. Lock Elements Coordinate Blocks (by Fine Grain Locking)
Figure 9 - 10. Lock Elements Coordinate Blocks (by Fine Grain Locking)
The foreground process checks in the SGA to see if the instance owns a lock on the block.
The V$LOCK_ELEMENT table shows the status of the lock elements.
You can selectively apply hashed and fine grain locking on different files. For example, you could apply locks as follows on a set of files:
GC_FILES_TO_LOCKS = "1=100:2=0:3=1000:4-5=0EACH" GC_RELEASABLE_LOCKS=10000
| File Number | Locking Mode | Value in GC_FILES_TO_LOCKS |
| 1 | Hashed | 100 |
| 2 | Fine grain | 0 |
| 3 | Hashed | 1000 |
| 4 | Fine grain | 0 |
| 5 | Fine grain | 0 |
For example:
GC_DB_LOCKS = 1000
GC_FILES_TO_LOCKS="1=500:5=200"
Example 1
The following dynamic performance table maps each file number to a bucket (index) in the X$KCLFH dynamic performance table. The default bucket number is 0. If the file is specified in GC_FILES_TO_LOCKS it will be assigned a bucket number.
| File Number | Bucket |
| 1 | 1 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| 5 | 2 |
In the following dynamic performance table Oracle finds the number of locks assigned to each bucket, as determined by GC_FILES_TO_LOCKS. Bucket 0 obtains all the remaining locks (GC_DB_LOCKS minus GC_FILES_TO_LOCKS: in this example, 1000 - 700 = 300). For each specified entry in GC_FILES_TO_LOCKS there is an entry in the X$KCLFH table. The grouping factor is determined by the ! option in the GC_FILES_TO_LOCKS strings.
| Bucket | Locks | Grouping | Start |
| 0 | 300 | 1 | 0 |
| 1 | 500 | 1 | 300 |
| 2 | 200 | 1 | 800 |
Example 2
Here is a further example of how hashed locks are assigned to blocks.
If GC_FILES_TO_LOCKS were set to "1-3=500:4-5=200!5EACH", then the structures would look like this:
| File Number | Bucket |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 3 |
The value 1 - 3 = 500 means that the files (1, 2, and 3) will share 500 locks between them. That is why files 1, 2, and 3 point to bucket 1. The value 4 - 5 = 200!5EACH means that file 4 and file 5 will each have 200 blocks. That is why file 4 points to bucket 2 and file 5 points to bucket 5.
| Bucket | Locks | Grouping | Start |
| 0 | 100 | 1 | 0 |
| 1 | 500 | 1 | 100 |
| 2 | 200 | 5 | 600 |
| 3 | 200 | 5 | 800 |
The !5 for files 4 and 5 is the grouping factor for each file. In this example 100 locks are not explicitly assigned, but are associated with bucket 0. These locks can be used for datafiles which may be added while the database is running.
Note: The X$ dynamic performance tables used in these examples are unsupported, and may change in future releases.
SELECT CLASS, COUNT(*) FROM V$LOCK_ELEMENT GROUP BY CLASS
ORDER BY CLASS;
The following query shows the number of hashed PCM locks:
SELECT COUNT(*)
FROM V$LOCK_ELEMENT
WHERE bitand(flag, 4)!=0;
The following query shows the number of fine grain PCM locks:
SELECT COUNT(*)
FROM V$LOCK_ELEMENT
WHERE bitand(flag, 4)=0;
 Other block classes are hashed to lock element numbers as follows:
Other block classes are hashed to lock element numbers as follows:
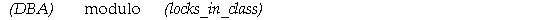 The following procedure finds the lock element number based on the database address and class of a block:
The following procedure finds the lock element number based on the database address and class of a block:
CREATE OR REPLACE PROCEDURE DBA_TO_LE (DBA IN NUMBER,
CLASS IN NUMBER, LE IN OUT NUMBER) IS
BASE NUMBER;
LOCKS NUMBER;
BEGIN
IF CLASS = 1
THEN
SELECT H.KCLFHBAS+MOD ((DBA/H.KCLFHGRP),H.KCLFHSIZ)
INTO LE
FROM X$KCLFI I, X$KCLFH H
WHERE I.INDX =
DBMS_UTILITY.DATA_BLOCK_ADDRESS_FILE(DBA)
AND I.KCLFIBUK = H.INDX;
END IF;
IF CLASS = 2
THEN
LE := -1;
END IF;
IF CLASS = 3 OR CLASS = 4 OR CLASS = 5 OR CLASS = 6
THEN
SELECT MIN(INDX), COUNT (*)
INTO BASE, LOCKS
FROM X$LE
WHERE LE_CLASS = CLASS;
LE := BASE + MOD(DBA, LOCKS);
END IF;
IF CLASS > 6
THEN
IF MOD(CLASS, 2) = 1
THEN
SELECT INDX
INTO LE
FROM X$LE
WHERE LE_CLASS = CLASS;
END IF;
IF MOD(CLASS, 2) = 0
THEN
SELECT MIN(INDX), COUNT(*)
INTO BASE, LOCKS
FROM X$LE
WHERE LE_CLASS = CLASS;
LE := BASE + MOD(DBA, LOCKS;
END IF;
END IF;
END;
Note: These examples discuss very small sample files to illustrate important concepts. The actual files you manage will be significantly larger.
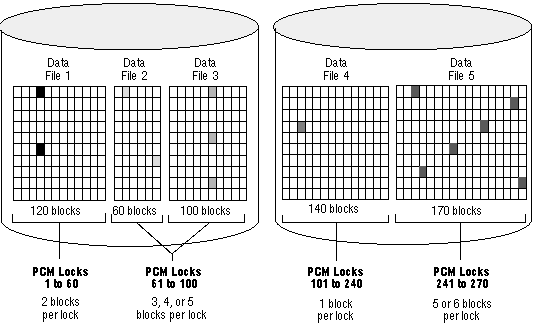 Figure 9 - 11. Mapping PCM Locks to Data Blocks
Figure 9 - 11. Mapping PCM Locks to Data Blocks
Example 1
Figure 9 - 11 shows an example of mapping blocks to PCM locks for the parameter value GC_FILES_TO_LOCKS = "1=60:2-3=40:4=140:5=30".
In datafile 1 of the figure, 60 PCM locks map to 120 blocks, which is a multiple of 60. Each PCM lock therefore covers two data blocks.
In datafiles 2 and 3, 40 PCM locks map to a total of 160 blocks. A PCM lock can cover either one or two data blocks in datafile 2, and two or three data blocks in datafile 3. Thus, one PCM lock may cover three, four, or five data blocks across both datafiles.
In datafile 4, each PCM lock maps exactly to a single data block, since there is the same number of PCM locks as data blocks.
In datafile 5, 30 PCM locks map to 170 blocks, which is not a multiple of 30. Each PCM lock therefore covers five or six data blocks.
Each of the PCM locks illustrated in Figure 9 - 11 can be held in either read-lock mode or read-exclusive mode.
Example 2
The following parameter value allocates 500 PCM locks to datafile 1; 400 PCM locks each to files 2, 3, 4, 10, 11, and 12; 150 PCM locks to file 5; 250 PCM locks to file 6; and 300 PCM locks collectively to files 7 through 9:
GC_FILES_TO_LOCKS = "1=500:2-4,10-12=400EACH:5=150:6=250:7-9=300"
This example assigns a total of (500 + (6*400) + 150 + 250 + 300) = 3600 PCM locks; therefore, the value of GC_DB_LOCKS must be at least 3600. You may specify more than this number of PCM locks if you intend to add more datafiles later.
Example 3
In Example 2, 300 PCM locks are allocated to datafiles 7, 8, and 9 collectively with the clause "7-9=300". The keyword EACH is omitted. If each of these datafiles contains 900 data blocks, for a total of 2700 data blocks, then each PCM lock covers 9 data blocks. Because the datafiles are multiples of 300, the 9 data blocks covered by the PCM lock are spread across the 3 datafiles; that is, one PCM lock covers 3 data blocks in each datafile.
Example 4
The following parameter value allocates 200 PCM locks each to files 1 through 3; 50 PCM locks to datafile 4; 100 PCM locks collectively to datafiles 5, 6, 7, and 9; and 20 data locks in contiguous 50-block groups to datafiles 8 and 10 combined:
GC_FILES_TO_LOCKS = "1-3=200EACH:4=50:5-7,9=100:8,10=20!50"
In this example, a PCM lock assigned to the combined datafiles 5, 6, 7, and 9 covers one or more data blocks in each datafile, unless a datafile contains fewer than 100 data blocks. If datafiles 5 to 7 contain 500 data blocks each and datafile 9 contains 100 data blocks, then each PCM lock covers 16 data blocks: one in datafile 9 and five each in the other datafiles. Alternatively, if datafile 9 contained 50 data blocks, half of the PCM locks would cover 16 data blocks (one in datafile 9); the other half of the PCM locks would only cover 15 data blocks (none in datafile 9).
The 20 PCM locks assigned collectively to datafiles 8 and 10 cover contiguous groups of 50 data blocks. If the datafiles contain multiples of 50 data blocks and the total number of data blocks is not greater than 20 times 50 (that is, 1000), then each PCM lock covers data blocks in either datafile 8 or datafile 10, but not in both. This is because each of these PCM locks covers 50 contiguous data blocks. If the size of datafile 8 is not a multiple of 50 data blocks, then one PCM lock must cover data blocks in both files. If the sizes of datafiles 8 and 10 exceed 1000 data blocks, then some PCM locks must cover more than one group of 50 data blocks, and the groups might be in different files.
Example 5
GC_FILES_TO_LOCKS="1-2=4"
In this example four locks are specified for files 1 and 2. Therefore, the number of blocks covered by each lock is 8 ((16+16)/4). The blocks are not contiguous.
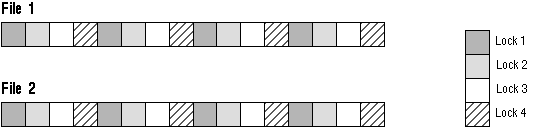 Figure 9 - 12. GC_FILES_TO_LOCKS Example 5
Figure 9 - 12. GC_FILES_TO_LOCKS Example 5
Example 6
GC_FILES_TO_LOCKS="1-2=4!8"
In this example four locks are specified for files 1 and 2. However, the locks must cover 8 contiguous blocks.
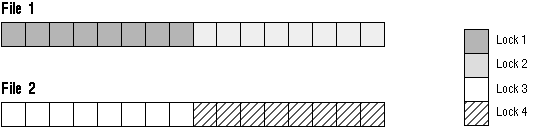 Figure 9 - 13. GC_FILES_TO_LOCKS Example 6
Figure 9 - 13. GC_FILES_TO_LOCKS Example 6
Example 7
GC_FILES_TO_LOCKS="1-2=4!4EACH"
In this example four locks are specified for file 1 and four for file 2. The locks must cover 4 contiguous blocks.
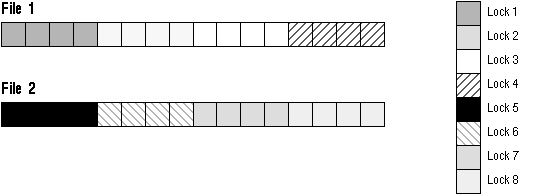 Figure 9 - 14. GC_FILES_TO_LOCKS Example 7
Figure 9 - 14. GC_FILES_TO_LOCKS Example 7
Example 8
GC_FILES_TO_LOCKS="1=4:2=0"
File 1 has hashed PCM locking with 4 locks. On file 2, fine grain locks are allocated on demand--none are initially allocated.
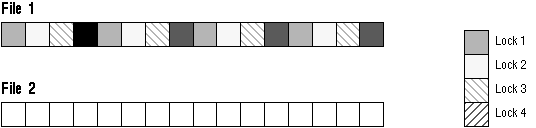 Figure 9 - 15. GC_FILES_TO_LOCKS Example 8
Figure 9 - 15. GC_FILES_TO_LOCKS Example 8
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |