| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
| Oracle7 Parallel Server Concepts and Administrator's Guide | Library |
Product |
Contents |
Index |
![]()
![]()
The parallel query option can run with or without the Oracle Parallel Server option. Without the parallel server option, Oracle7 is optimized to run on SMP hardware. The parallel server option optimizes Oracle7 to run on clustered or MPP hardware, using a parallel cache architecture to avoid shared memory bottlenecks in OLTP and decision support applications. The parallel query option can parallelize queries on SMP machines and on MPP machines with the parallel server option, with linear speedup and scaleup of query performance.
The parallel query option does not require the parallel server option. However, some aspects of the parallel query option apply only to a parallel server.
Various strategies for parallel processing are possible. This section contrasts external parallelism (static partitioning) with internal parallelism (dynamic partitioning), which is supported by Oracle Parallel Server. The key distinction between these two architectures is: Who parallelizes the query--an external or an internal process.
See Also: Oracle7 Server Tuning for more information about the Parallel Query Option.
Figure 13 - 1 illustrates external architecture for an MPP or cluster system running a decision support application.
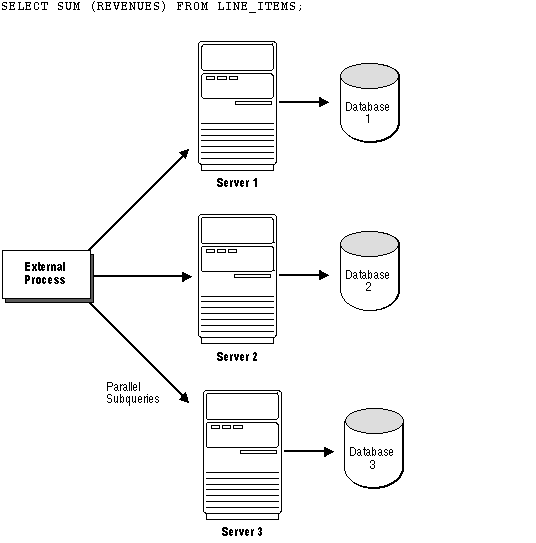 Figure 13 - 1. External Parallelism for Query Processing: A DSS Application
Figure 13 - 1. External Parallelism for Query Processing: A DSS Application
Figure 13 - 2 illustrates external architecture for a symmetric multiprocessor, with physically separate databases.
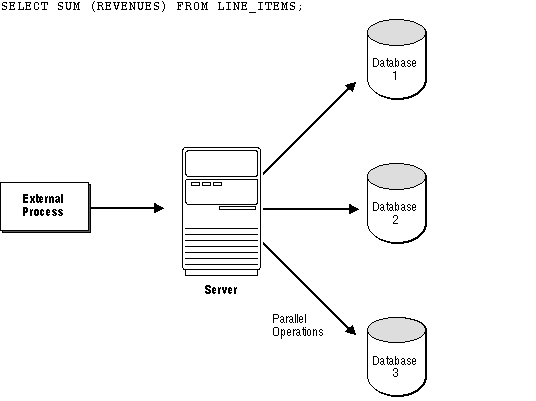 Figure 13 - 2. External Parallelism for a Symmetric Multiprocessor.
Figure 13 - 2. External Parallelism for a Symmetric Multiprocessor.
External parallelism was designed to support parallel "shared-nothing" hardware architectures, in which each CPU has dedicated memory and disks. To execute queries rapidly, external parallelism separates a database into several sections, each of which is associated with a specific processor and memory.
Note: Hardware architectures are discussed in the chapter "Parallel Hardware Architecture" ![[*]](jump.gif) .
.
The fact that each CPU has access to only a subset of the database means that the strategy used to partition data across disks also determines how query operations are parallelized across CPUs. Just as data is statically partitioned across disks, so query operations are statically partitioned across CPUs. At execution time, the query must be parallelized consistently with the way in which the data is partitioned, regardless of CPU utilization.
Because it was originally designed for hardware in which CPUs do not share disks, static partitioning is not appropriate for SMP or MPP shared-disk systems. On these machines, it is possible to allocate processing to different CPUs depending on their utilization at execution time, rather than allocating the processing according to how data is partitioned on the disks.
External parallelism has the following disadvantages:
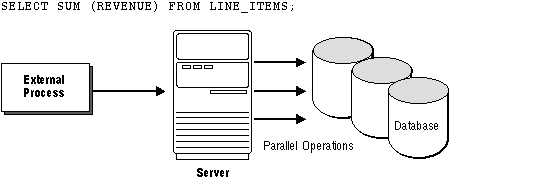 Figure 13 - 3. Internal Parallelism
Figure 13 - 3. Internal Parallelism
In contrast to external parallelism, internal parallelism (dynamic partitioning) can adjust the way a query is parallelized at execution time based on available CPU resources. As a result, it efficiently uses CPU resources to reduce query response times. Unlike static architectures, dynamic methods avoid the unbalanced parallelism that occurs when the partitioning of data does not match CPU resources.
With dynamic partitioning, it is not as important to anticipate the types of queries that an application will request. Because the data server can adjust how operations are parallelized, application developers need not be as concerned with how they partition data across disks. Oracle7 parallel data management can take advantage of disk striping performed by the operating system and does not require manual data partitioning. If requirements change, database administrators do not need to unload data, change keys, and repartition the data.
In addition, a dynamic architecture can benefit all types of queries--including pre-planned queries and ad hoc queries. Internal architectures tend to handle ad hoc queries more efficiently than external architectures. When a query needs to parallelize operations differently from the way data is partitioned on disk (such as sorting on a non-key value), external architectures must ship data between many processors. In contrast, internal architectures can repartition the data within the data server, which requires less processing overhead. For example, if sales data is partitioned across the disks according to month, and an ad hoc query concerning December sales data is issued, a dynamic architecture would parallelize the scan efficiently across CPUs.
In contrast to external parallelism, an internal architecture avoids maintaining a separate database for each CPU. Maintaining separate databases with large numbers of processors adds significant database management overhead in the areas of configuration, maintenance, and cost. In addition the scaleup and speedup capabilities of applications (as CPUs are added) generally degrade when using external parallelism, since additional data servers and databases result in additional processing overhead.
Finally, internal parallelism preserves all server functions, unlike external parallelism. External parallelism requires management of two different elements for each function, such as security and data replication.
Internal parallelism has the following advantages:
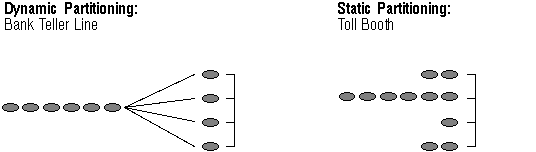 Figure 13 - 4. Static vs. Dynamic Partitioning for Query Parallelization
Figure 13 - 4. Static vs. Dynamic Partitioning for Query Parallelization
Dynamic partitioning (in an internal architecture) is like a bank teller line where customers are free to pick the next available teller. In this way, customers are not waiting for a particular teller when other windows are open. Similarly, operations in a transaction can pick the next available CPU without waiting for a particular CPU to become available.
Static partitioning (in an external architecture) is like a toll both, where cars pick a queue and cannot change their queues. Similarly, query operations are assigned a CPU based on how data is partitioned across disks, and must wait for their assigned CPU to perform their work.
| Dynamic Partitioning: Shared Disk Approach | Static Partitioning: Shared Nothing Approach |
| Partitions determined at query execution time. | Partitions determined at table creation time. |
| OS striping software can be used to divide large tables across different physical devices. | DBA must repartition the database in order to balance the I/O load as table size and workload vary. |
| Decomposes scan into different sized subscans and dynamically distributes each subscan to the next available process. | Preassigns subscans to processes; the subscans are determined by the DBA. |
| Flexible, minimizes DBA overhead. | DBA must monitor database constantly if workload varies and tables grow. |
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |