| Oracle7 Server Tuning | Library |
Product |
Contents |
Index |
| Oracle7 Server Tuning | Library |
Product |
Contents |
Index |
![]()
![]()
This appendix describes the Oracle Server parallel query feature, covering the topics:
Note: Parallel query is not the same as the Parallel Server option of the Oracle Server. The Parallel Server option is not required to use this feature. However, some aspects of the parallel query feature apply only to an Oracle Parallel Server.
The parallel query feature can dramatically improve performance for data-intensive operations associated with decision support applications or very large database environments. Symmetric multiprocessing (SMP), clustered, or massively parallel systems gain the largest performance benefits from the parallel query feature because query processing can be effectively split up among many CPUs on a single system.
It is important to note that the query is parallelized dynamically at execution time. Thus, if the distribution or location of the data changes, Oracle automatically adapts to optimize the parallelization for each execution of a SQL statement.
The parallel query feature helps systems scale in performance when adding hardware resources. If your system's CPUs and disk controllers are already heavily loaded, you need to alleviate the system's load before using the parallel query feature to improve performance. Chapter 18, "Parallel Query Tuning" describes how your system can achieve the best performance with the parallel query feature.
The Oracle Server can use parallel query processing for any of these statements:
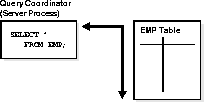
The following figure illustrates several query server processes simultaneously performing a partial scan of the EMP table. The results are then sent back to the query coordinator, which assembles the pieces into the desired full table scan.
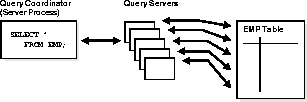
The query coordinator calls upon the query servers during the execution of the SQL statement (not during the parsing of the statement). Therefore, when using the parallel query feature with the multi-threaded server, the server processing the EXECUTE call of a user's statement becomes the query coordinator for the statement.
The following figure illustrates creating a table from a subquery in parallel.
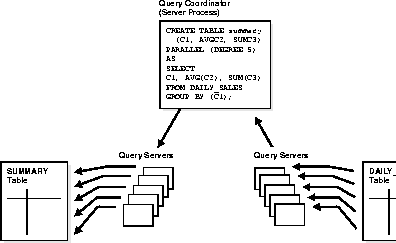
Clustered tables cannot be created and populated in parallel.
For a discussion of the syntax of the CREATE TABLE command, see the Oracle7 Server SQL Reference.
When creating a table in parallel, each of the query server processes uses the values in the STORAGE clause. Therefore, a table created with an INITIAL of 5M and a PARALLEL DEGREE of 12 consumes at least 60M of storage during table creation because each process starts with an extent of 5M. When the query coordinator process combines the extents, some of the extents may be trimmed, and the resulting table may be smaller than the requested 60M.
For more information on how extents are allocated when using the parallel query feature, see Oracle7 Server Concepts.
To decide how to parallelize a statement, the query coordinator process must decide whether to enlist query server processes and, if so, how many query server processes to enlist. When making these decisions, the query coordinator uses information specified in hints of a query, the table's definition, and initialization parameters. The precedence for selecting the degree of parallelism is described later in this section. It is important to note that the optimizer attempts to parallelize a query only if it contains at least one full table scan operation.
SELECT dname, MAX(sal), AVG(sal)
FROM emp, dept
WHERE emp.deptno = dept.deptno
GROUP BY dname;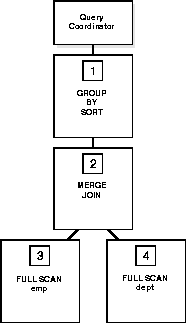
Data Flow Diagram for a Join of the EMP and DEPT Tables
Operations that require the output of other operations are known as parent operations. In Figure C-4 the GROUP BY SORT operation is the parent of the MERGE JOIN operation because GROUP BY SORT requires the MERGE JOIN output.
Due to the producer/consumer nature of the Oracle Server's query operations, only two operations in a given tree need to be performed simultaneously to minimize execution time.
To illustrate intra-operation parallelism and inter-operator parallelism, consider the following statement:
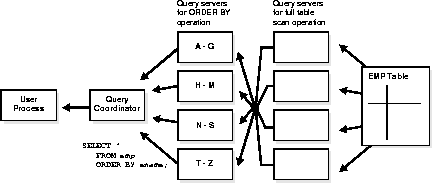
SELECT * FROM emp ORDER BY ename;
The execution plan consists of a full scan of the EMP table followed by a sorting of the retrieved rows based on the value of the ENAME column. For the sake of this example, assume the ENAME column is not indexed. Also assume that the degree of parallelism for the query is set to four, which means that four query servers can be active for any given operation. Figure C-5 illustrates the parallel execution of our example query.
As you can see from Figure C-5, there are actually eight query servers involved in the query even though the degree of parallelism is four. This is because a parent and child operator can be performed at the same time. Also note that all of the query servers involved in the scan operation send rows to the appropriate query server performing the sort operation. If a row scanned by a query server contains a value for the ENAME column between A and G, that row gets sent to the first ORDER BY query server. When the scan operation is complete, the sorting query servers can return the sorted results to the query coordinator, which in turn returns the complete query results to the user.
For queries involving more than one table, the query coordinator requests the greatest number specified for any table in the query. For example, on a query joining the EMP and DEPT tables, if EMP's degree of parallelism is specified as 5 and DEPT's degree of parallelism is specified as 6, the query coordinator would request six query servers for each operation in the query.
Keep in mind that no more than two operations can be performed simultaneously. Therefore, the maximum number of query servers requested for any query can be up to twice the degree of parallelism per instance.
Hints, the table definitions, or initialization parameters only determine the number of query servers that the query coordinator requests for a given operation. The actual number of query servers used depends upon how many query servers are available in the query server pool and whether inter-operation parallelism is possible.
When you create a table and populate it with a subquery in parallel, the degree of parallelism for the population is determined by the table's degree of parallelism. If no degree of parallelism is specified in the newly created table, the degree of parallelism is derived from the subquery's parallelism. If the subquery cannot be parallelized, the table is created serially.
For example, your system has 20 CPUs and you issue a parallel query on a table that is stored on 15 disk drives. The default degree of parallelism for your query is 15 query servers.
Note: The parameters PARALLEL_DEFAULT_SCANSIZE and PARALLEL_DEFAULT_MAX_SCANS are obsolete in release 7.3.
Specify the desired minimum percentage of requested query servers with the initialization parameter PARALLEL_QUERY_MIN_PERCENT. For example, if you specify 50 for this parameter, then at least 50% of the query servers requested for any parallel operation must be available in order for the operation to succeed. If 20 query servers are requested, then at least 10 must be available or an error is returned to the user. If the value of PARALLEL_QUERY_MIN_PERCENT is set to null, then all parallel operations will proceed as long as at least two query servers are available for processing.
If you want to specify the number of instances to participate in parallel query processing at startup time, you can specify a value for the initialization parameter PARALLEL_DEFAULT_MAX_INSTANCES. See the Oracle7 Server Reference for more information about this parameter.
If you want to limit the number of instances available for parallel query processing dynamically, use the ALTER SYSTEM command. For example, if you have ten instances running in your Parallel Server, but you want only eight to be involved in parallel query processing, you can specify a value by issuing the following command:
ALTER SYSTEM SET SCAN_INSTANCES = 8;
Therefore, if a table's definition has a value of ten specified in the INSTANCES keyword, the table will be scanned by query servers on eight of the ten instances. Oracle selects the first eight instances in this example. Set the parameter PARALLEL_MAX_SERVERS to zero on the instances that you do not want to participate in parallel query processing.
If you wish to limit the number of instances that cache a table, you can issue the following command:
ALTER SYSTEM SET CACHE_INSTANCES = 8;
Therefore, if a table specifies the CACHE keyword with the INSTANCES keyword specified as 10, it will divide evenly among eight of the ten available instances' buffer caches.
Query server processes remain associated with a statement throughout its execution phase. When the statement is completely processed, its query server processes become available to process other statements. The query coordinator process returns any resulting data to the user process issuing the statement.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |