| Oracle7 Server Tuning | Library |
Product |
Contents |
Index |
| Oracle7 Server Tuning | Library |
Product |
Contents |
Index |
![]()
![]()
Constants Any computation of constants is performed only once when the statement is optimized rather than each time the statement is executed. Consider these conditions that test for monthly salaries greater than 2000:
sal > 24000/12
sal > 2000
sal*12 > 24000
If a SQL statement contains the first condition, the optimizer simplifies it into the second condition.
Note that the optimizer does not simplify expressions across comparison operators. The optimizer does not simplify the third expression into the second. For this reason, application developers should write conditions that compare columns with constants whenever possible, rather than conditions with expressions involving columns.
LIKE The optimizer simplifies conditions that use the LIKE comparison operator to compare an expression with no wildcard characters into an equivalent condition that uses an equality operator instead. For example, the optimizer simplifies the first condition below into the second:
ename LIKE 'SMITH'
ename = 'SMITH'
The optimizer can simplify these expressions only when the comparison involves variable-length datatypes. For example, if ENAME was of type CHAR(10), the optimizer cannot transform the LIKE operation into an equality operation due to the comparison semantics of fixed-length datatypes.
IN The optimizer expands a condition that uses the IN comparison operator to an equivalent condition that uses equality comparison operators and OR logical operators. For example, the optimizer expands the first condition below into the second:
ename IN ('SMITH', 'KING', 'JONES')
ename = 'SMITH' OR ename = 'KING' OR ename = 'JONES'
ANY or SOME The optimizer expands a condition that uses the ANY or SOME comparison operator followed by a parenthesized list of values into an equivalent condition that uses equality comparison operators and OR logical operators. For example, the optimizer expands the first condition below into the second:
sal > ANY (:first_sal, :second_sal)
sal > :first_sal OR sal > :second_sal
The optimizer transforms a condition that uses the ANY or SOME operator followed by a subquery into a condition containing the EXISTS operator and a correlated subquery. For example, the optimizer transforms the first condition below into the second:
x > ANY (SELECT sal
FROM emp
WHERE job = 'ANALYST')
EXISTS (SELECT sal
FROM emp
WHERE job = 'ANALYST'
AND x > sal)
ALL The optimizer expands a condition that uses the ALL comparison operator followed by a parenthesized list of values into an equivalent condition that uses equality comparison operators and AND logical operators. For example, the optimizer expands the first condition below into the second:
sal > ALL (:first_sal, :second_sal)
sal > :first_sal AND sal > :second_sal
The optimizer transforms a condition that uses the ALL comparison operator followed by a subquery into an equivalent condition that uses the ANY comparison operator and a complementary comparison operator. For example, the optimizer transforms the first condition below into the second:
x > ALL (SELECT sal
FROM emp
WHERE deptno = 10)
NOT (x <= ANY (SELECT sal
FROM emp
WHERE deptno = 10) )
The optimizer then transforms the second query into the following query using the rule for transforming conditions with the ANY comparison operator followed by a correlated subquery:
NOT EXISTS (SELECT sal
FROM emp
WHERE deptno = 10
AND x <= sal)
BETWEEN The optimizer always replaces a condition that uses the BETWEEN comparison operator with an equivalent condition that uses the >= and <= comparison operators. For example, the optimizer replaces the first condition below with the second:
sal BETWEEN 2000 AND 3000
sal >= 2000 AND sal <= 3000
NOT The optimizer simplifies a condition to eliminate the NOT logical operator. The simplification involves removing the NOT logical operator and replacing a comparison operator with its opposite comparison operator. For example, the optimizer simplifies the first condition below into the second one:
NOT deptno = (SELECT deptno FROM emp WHERE ename = 'TAYLOR')
deptno <> (SELECT deptno FROM emp WHERE ename = 'TAYLOR')
Often a condition containing the NOT logical operator can be written many different ways. The optimizer attempts to transform such a condition so that the subconditions negated by NOTs are as simple as possible, even if the resulting condition contains more NOTs. For example, the optimizer simplifies the first condition below into the second and then into the third.
NOT (sal < 1000 OR comm IS NULL)
NOT sal < 1000 AND comm IS NOT NULL
sal >= 1000 AND comm IS NOT NULL
Transitivity If two conditions in the WHERE clause involve a common column, the optimizer can sometimes infer a third condition using the transitivity principle. The optimizer can then use the inferred condition to optimize the statement. The inferred condition could potentially make available an index access path that was not made available by the original conditions.
Imagine a WHERE clause containing two conditions of these forms:
WHERE column1 comp_oper constant
AND column1 = column2
In this case, the optimizer infers the condition
column2 comp_oper constant
where:
Note: Transitivity is used only by the cost-based approach.
SELECT *
FROM emp, dept
WHERE emp.deptno = 20
AND emp.deptno = dept.deptno;
dept.deptno = 20
WHERE column1 comp_oper column3
AND column1 = column2
column2 comp_oper column3
If a query contains a WHERE clause with multiple conditions combined with OR operators, the optimizer transforms it into an equivalent compound query that uses the UNION ALL set operator if this will make it execute more efficiently:
Example: Consider this query with a WHERE clause that contains two conditions combined with an OR operator:
SELECT *
FROM emp
WHERE job = 'CLERK'
OR deptno = 10;
SELECT *
FROM emp
WHERE job = 'CLERK'
UNION ALL
SELECT *
FROM emp
WHERE deptno = 10
AND job <> 'CLERK';
Execution Plan for a Compound Query
To execute the transformed query, Oracle performs these steps:
Example: Consider this query and assume there is an index on the ENAME column:
SELECT *
FROM emp
WHERE ename = 'SMITH'
OR sal > comm;
Transforming the query above would result in the compound query below:
SELECT *
FROM emp
WHERE ename = 'SMITH'
UNION ALL
SELECT *
FROM emp
WHERE sal > comm;
Since the condition in the WHERE clause of the second component query (SAL > COMM) does not make an index available, the compound query requires a full table scan. For this reason, the optimizer does not consider making the transformation and chooses a full table scan to execute the original statement.
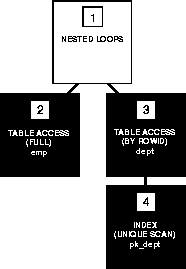
Consider this complex statement that selects all rows from the ACCOUNTS table whose owners appear in the CUSTOMERS table:
SELECT *
FROM accounts
WHERE custno IN
(SELECT custno FROM customers);
SELECT accounts.*
FROM accounts, customers
WHERE accounts.custno = customers.custno;
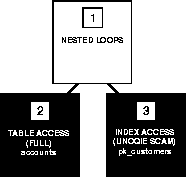
Execution Plan for a Nested Loops Join
To execute this statement, Oracle performs a nested loops join operation. For information on nested loops joins, see the section "Join Operations" on page A-37.
If the optimizer cannot transform a complex statement into a join statement, the optimizer chooses execution plans for the parent statement and the subquery as though they were separate statements. Oracle then executes the subquery and uses the rows it returns to execute the parent query.
SELECT *
FROM accounts
WHERE accounts.balance >
(SELECT AVG(balance) FROM accounts);
Merging the View's Query into the Accessing Statement To merge the view's query into the accessing statement, the optimizer replaces the name of the view with the name of its base table in the accessing statement and adds the condition of the view's query's WHERE clause to the accessing statement's WHERE clause.
Example: Consider this view of all employees who work in department 10:
CREATE VIEW emp_10
AS SELECT empno,ename, job, mgr, hiredate, sal, comm, deptno
FROM emp
WHERE deptno = 10;
Consider this query that accesses the view. The query selects the IDs greater than 7800 of employees who work in department 10:
SELECT empno
FROM emp_10
WHERE empno > 7800;
The optimizer transforms the query into the following query that accesses the view's base table:
SELECT empno
FROM emp
WHERE deptno = 10
AND empno > 7800;
If there are indexes on the DEPTNO or EMPNO columns, the resulting WHERE clause makes them available.
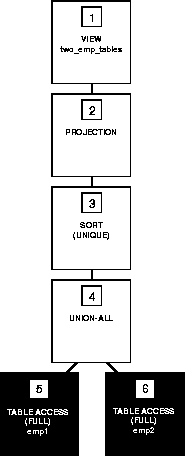
Merging the Accessing Statement into the View's Query The optimizer cannot always merge the view's query into the accessing statement. Such a transformation is not possible if the view's query contains
Example: Consider the TWO_EMP_TABLES view, which is the union of two employee tables. The view is defined with a compound query that uses the UNION set operator:
CREATE VIEW two_emp_tables
(empno, ename, job, mgr, hiredate, sal, comm, deptno) AS
SELECT empno, ename, job, mgr, hiredate, sal, comm,
deptno FROM emp1 UNION
SELECT empno, ename, job, mgr, hiredate, sal, comm,
deptno FROM emp2;
Consider this query that accesses the view. The query selects the IDs and names of all employees in either table who work in department 20:
SELECT empno, ename
FROM two_emp_tables
WHERE deptno = 20;
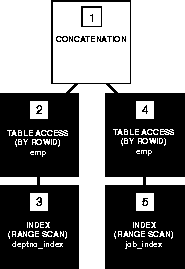
Since the view is defined as a compound query, the optimizer cannot merge the view query into the accessing query. Instead, the optimizer transforms the query by adding its WHERE clause condition into the compound query. The resulting statement looks like this:
SELECT empno, ename FROM emp1 WHERE deptno = 20
UNION
SELECT empno, ename FROM emp2 WHERE deptno = 20;
If there is an index on the DEPTNO column, the resulting WHERE clauses make it available. The following figure shows the execution plan of the resulting statement.
CREATE VIEW emp_group_by_deptno
AS SELECT deptno,
AVG(sal) avg_sal,
MIN(sal) min_sal,
MAX(sal) max_sal
FROM emp
GROUP BY deptno;
Consider this query, which selects the average, minimum, and maximum salaries of department 10 from the EMP_GROUP_BY_DEPTNO view:
SELECT *
FROM emp_group_by_deptno
WHERE deptno = 10;
The optimizer transforms the statement by adding its WHERE clause condition into the view's query. The resulting statement looks like this:
SELECT deptno,
AVG(sal) avg_sal,
MIN(sal) min_sal,
MAX(sal) max_sal,
FROM emp
WHERE deptno = 10
GROUP BY deptno;
If there is an index on the DEPTNO column, the resulting WHERE clause makes it available.
The following figure shows the execution plan for the resulting statement. The execution plan uses an index on the DEPTNO column.
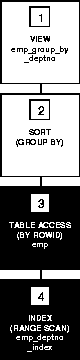
SELECT AVG(avg_sal), AVG(min_sal), AVG(max_sal)
FROM emp_group_by_deptno;
The optimizer transforms this statement by applying the AVG group function to the select list of the view's query:
SELECT AVG(AVG(sal)), AVG(MIN(sal)), AVG(MAX(sal))
FROM emp
GROUP BY deptno;
The following figure shows the execution plan of the resulting statement:

Example: Consider the EMP_GROUP_BY_DEPTNO view defined in the previous section:
CREATE VIEW emp_group_by_deptno
AS SELECT deptno,
AVG(sal) avg_sal,
MIN(sal) min_sal,
MAX(sal) max_sal
FROM emp
GROUP BY deptno;
Consider this query, which accesses the view. The query joins the average, minimum, and maximum salaries from each department represented in this view and to the name and location of the department in the DEPT table:
SELECT emp_group_by_deptno.deptno, avg_sal, min_sal,
max_sal, dname, loc
FROM emp_group_by_deptno, dept
WHERE emp_group_by_deptno.deptno = dept.deptno;
Since there is no equivalent statement that accesses only base tables, the optimizer cannot transform this statement. Instead, the optimizer chooses an execution plan that issues the view's query and then uses the resulting set of rows as it would the rows resulting from a table access.
The following figure shows the execution plan for this statement.
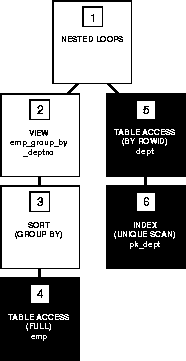
Note that PL/SQL ignores the OPTIMIZER_MODE=FIRST_ROWS initialization parameter setting.
The value of this parameter affects the optimization of SQL statements issued by stored procedures and functions called during the session, but it does not affect the optimization of recursive SQL statements that Oracle issues during the session. The optimization approach for recursive SQL statements is only affected by the value of the OPTIMIZER_MODE initialization parameter.
The optimizer can only choose to use a particular access path for a table if the statement contains a WHERE clause condition or other construct that makes that access path available. Each of the following sections describes an access path and discusses
Path 1: Single Row by ROWID This access path is only available if the statement's WHERE clause identifies the selected rows by ROWID or with the CURRENT OF CURSOR embedded SQL syntax supported by the Oracle Precompilers. To execute the statement, Oracle accesses the table by ROWID.
Example: This access path is available in the following statement:
SELECT * FROM emp WHERE ROWID = '00000DC5.0000.0001';
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
Path 2: Single Row by Cluster Join This access path is available for statements that join tables stored in the same cluster if both of these conditions are true:
Example: This access path is available for the following statement in which the EMP and DEPT tables are clustered on the DEPTNO column and the EMPNO column is the primary key of the EMP table:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno
AND emp.empno = 7900;
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
NESTED LOOPS
TABLE ACCESS BY ROWID EMP
INDEX UNIQUE SCAN PK_EMP
TABLE ACCESS CLUSTER DEPT
Example: This access path is available in the following statement, in which the ORDERS and LINE_ITEMS tables are stored in a hash cluster, and the ORDERNO column is both the cluster key and the primary key of the ORDERS table:
SELECT *
FROM orders
WHERE orderno = 65118968;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS HASH ORDERS
Path 4: Single Row by Unique or Primary Key This access path is available if the statement's WHERE clause uses all columns of a unique or primary key in equality conditions. For composite keys, the equality conditions must be combined with AND operators. To execute the statement, Oracle performs a unique scan on the index on the unique or primary key to retrieve a single ROWID and then accesses the table by that ROWID.
Example: This access path is available in the following statement in which the EMPNO column is the primary key of the EMP table:
SELECT *
FROM emp
WHERE empno = 7900;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX UNIQUE SCAN PK_EMP
PK_EMP is the name of the index that enforces the primary key.
Path 5: Clustered Join This access path is available for statements that join tables stored in the same cluster if the statement's WHERE clause contains conditions that equate each column of the cluster key in one table with the corresponding column in the other table. For a composite cluster key, the equality conditions must be combined with AND operators. To execute the statement, Oracle performs a nested loops operation. For information on nested loops operations, see the section "Join Operations" on page A-37.
Example: This access path is available in the following statement in which the EMP and DEPT tables are clustered on the DEPTNO column:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
NESTED LOOPS
TABLE ACCESS FULL DEPT
TABLE ACCESS CLUSTER EMP SELECT *
FROM line_items
WHERE orderno = 65118968;OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS HASH LINE_ITEMS SELECT * FROM emp
WHERE deptno = 10;OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS CLUSTER EMP
INDEX UNIQUE SCAN PERS_INDEX
SELECT *
FROM emp
WHERE job = 'CLERK'
AND deptno = 30;
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX RANGE SCAN JOB_DEPTNO_INDEX
SELECT *
FROM emp
WHERE job = 'ANALYST';
OPERATION OPTION OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX RANGE SCAN JOB_INDEX SELECT *
FROM emp
WHERE job = 'ANALYST'
AND deptno = 20;OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
AND-EQUAL
INDEX RANGE SCAN JOB_INDEX
INDEX RANGE SCAN DEPTNO_INDEX
column = expr
column >[=] expr AND column <[=] expr
column BETWEEN expr AND expr
column LIKE 'c%'
SELECT *
FROM emp
WHERE sal BETWEEN 2000 AND 3000;
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX RANGE SCAN SAL_INDEX SELECT *
FROM emp
WHERE ename LIKE 'S%';
WHERE column >[=] expr
WHERE column <[=] expr
SELECT *
FROM emp
WHERE sal > 2000;OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX RANGE SCAN SAL_INDEX SELECT *
FROM line_items
WHERE order > 65118968;
SELECT *
FROM line_items
WHERE line < 4;
Example: This access path is available for the following statement in which the EMP and DEPT tables are not stored in the same cluster:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
MERGE JOIN
SORT JOIN
TABLE ACCESS FULL EMP
SORT JOIN
TABLE ACCESS FULL DEPT
Example: This access path is available for the following statement in which there is an index on the SAL column of the EMP table:
SELECT MAX(sal) FROM emp;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
AGGREGATE GROUP BY
INDEX RANGE SCAN SAL_INDEX
Path 14: ORDER BY on Indexed Column This access path is available for a SELECT statement for which all of these conditions are true:
Example: This access path is available for the following statement in which there is a primary key on the EMPNO column of the EMP table:
SELECT *
FROM emp
ORDER BY empno;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX RANGE SCAN PK_EMP
PK_EMP is the name of the index that enforces the primary key. The primary key ensures that the column does not contain nulls.
Path 15: Full Table Scan This access path is available for any SQL statement, regardless of its WHERE clause conditions.
This statement uses a full table scan to access the EMP table:
SELECT *
FROM emp;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS FULL EMP
Note that these conditions do not make index access paths available:
Example: Consider this query, which uses a bind variable rather than a literal value for the boundary value in the WHERE clause condition:
SELECT *
FROM emp
WHERE empno < :e1;
The optimizer does not know the value of the bind variable E1. Indeed, the value of E1 may be different for each execution of the query. For this reason, the optimizer cannot use the means described in the previous example to determine selectivity of this query. In this case, the optimizer heuristically guesses a small value for the selectivity of the column (because it is indexed). The optimizer makes this assumption whenever a bind variable is used as a boundary value in a condition with one of the operators <, >, <=, or >=.
The optimizer's treatment of bind variables can cause it to choose different execution plans for SQL statements that differ only in the use of bind variables rather than constants. In one case in which this difference may be especially apparent, the optimizer may choose different execution plans for an embedded SQL statement with a bind variable in an Oracle Precompiler program and the same SQL statement with a constant in SQL*Plus.
Example: Consider this query, which uses two bind variables as boundary values in the condition with the BETWEEN operator:
SELECT *
FROM emp
WHERE empno BETWEEN :low_e AND :high_e;
The optimizer decomposes the BETWEEN condition into these two conditions:
empno >= :low_e
empno <= :high_e
The optimizer heuristically estimates a small selectiviy for indexed columns in order to favor the use of the index.
Example: Consider this query, which uses the BETWEEN operator to select all employees with employee ID numbers between 7500 and 7800:
SELECT *
FROM emp
WHERE empno BETWEEN 7500 AND 7800;
To determine the selectivity of this query, the optimizer decomposes the WHERE clause condition into these two conditions:
empno >= 7500
empno <= 7800
The optimizer estimates the individual selectivity of each condition using the means described in a previous example. The optimizer then uses these selectivities (S1 and S2) and the absolute value function (ABS) in this formula to estimate the selectivity (S) of the BETWEEN condition:
S = ABS( S1 + S2 - 1 )
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
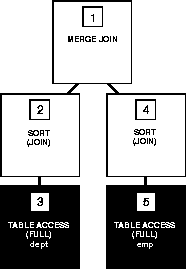
The following figure shows the execution plan for this statement using a sort-merge join:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
The following figure shows the execution plan for this statement in which the EMP and DEPT tables are stored together in the same cluster:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;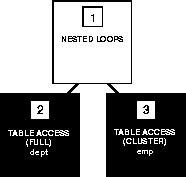
Cluster Join
To execute this statement, Oracle performs these steps:
Hash Join To perform a hash join, Oracle follows these steps:
The following figure shows the execution plan for this statement using a hash join:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
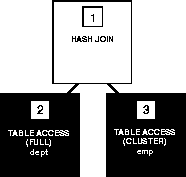
The initialization parameter HASH_AREA_SIZE controls the memory to be used for hash join operations and the initialization parameter HASH_MULTIBLOCK_IO_COUNT controls the number of blocks a hash join operation should read and write concurrently. See Oracle7 Server Reference for more information about these initialization parameters.
2. a. The optimizer chooses the execution plan with the fewest nested-loops operations in which the inner table is accessed with a full table scan.
2. b. If there is a tie, the optimizer chooses the execution plan with the fewest sort-merge operations.
2. c. If there is still a tie, the optimizer chooses the execution plan for which the first table in the join order has the most highly ranked access path:
A "star join" refers to a primary key to foreign key join of the dimension tables to a fact table. The fact table normally has a concatenated index on the key columns to facilitate this type of join.
The Oracle cost-based optimizer recognizes such star queries and generates efficient execution plans for them.
SELECT SUM(dollars) FROM facts, time, product, market
WHERE market.stat = 'New York' AND
product.brand = 'MyBrand' AND
time.year = 1995 AND time.month = 'March' AND
/* Joins*/
time.key = facts.tkey AND
product.pkey = facts.pkey AND
market.mkey = facts.mkey;
A star query is thus a join between a very large table and a number of much smaller "lookup" tables. Each lookup table is joined to the large table using a primary key to foreign key join, but the small tables are not joined to each other.
If all queries specify predicates on each of the small tables, a single concatenated index suffices. If queries that omit leading columns of the concatenated index are frequent, additional indexes may be useful. In this example, if there are frequent queries that omit the time table, an index on pkey and mkey can be added.
CREATE VIEW prodview AS SELECT /*+ NO_MERGE */ *
FROM brands, mfgrs WHERE brands.mfkey = mfgrs.mfkey;
This hint will both reduce the optimizer's search space, and cause caching of the result of the view.
/*+ ORDERED USE_NL(facts) INDEX(facts fact_concat) */
A more general method is to use the STAR hint /*+ STAR */.
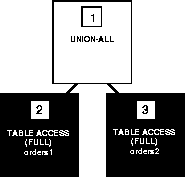
The following figure shows the execution plan for this statement, which uses the UNION ALL operator to select all occurrences of all parts in either the ORDERS1 table or the ORDERS2 table:
SELECT part FROM orders1
UNION ALL
SELECT part FROM orders2;
SELECT part FROM orders1
UNION
SELECT part FROM orders2;
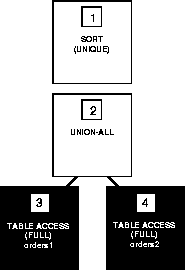
Figure A-13 shows the execution plan for this statement, which uses the INTERSECT operator to select only those parts that appear in both the ORDERS1 and ORDERS2 tables:
SELECT part FROM orders1
INTERSECT
SELECT part FROM orders2;
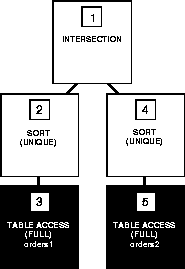
Compound Query with INTERSECT Set Operator
To execute this statement, Oracle performs these steps:
For example, suppose that the values in a single column of a 1000-row table range between 1 and 100, and suppose that you want a 10-bucket histogram (ranges in a histogram are often referred to as "buckets"). In a width-balanced histogram, the buckets would be of equal width (1-10, 11-20, 21,-30, etc.) and each bucket would count the number of rows that fall into that range. In a height-balanced histogram, each bucket has the same height (in this case 100 rows), and then the endpoints for the buckets would be determined by the density of the distinct values in the column.
If you wanted to know how many rows in the table contained the value "5", it is apparent from the height-balanced histogram that approximately 80% of the rows contain this value. However, the width-balanced histogram does not provide a mechanism for differentiating between the value "5" and the value "6". You would compute only 8% of the rows contain the value "5" in a width-balanced histogram. Thus, height-balanced histograms are more appropriate for determining the selectivity of column values.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |