| Oracle7 Server Tuning | Library |
Product |
Contents |
Index |
| Oracle7 Server Tuning | Library |
Product |
Contents |
Index |
![]()
![]()
See Also: For more information on creating clusters, see the Oracle7 Server Application Developer's Guide.
When you create a hash cluster, you must use the HASHKEYS parameter of the CREATE CLUSTER statement to specify the number of hash values for the hash cluster. For best performance of hash scans, choose a HASHKEYS value that is at least as large as the number of cluster key values. Such a value reduces the chance of collisions, or multiple cluster key values resulting in the same hash value. Collisions force Oracle to test the rows in each block for the correct cluster key value after performing a hash scan. Collisions reduce the performance of hash scans.
Oracle always rounds up the HASHKEYS value that you specify to the nearest prime number to obtain the actual number of hash values. This rounding is designed to reduce collisions.
See Also: For more information on creating hash clusters, see the Oracle7 Server Application Developer's Guide.
See Also: "ALWAYS_ANTI_JOIN" on page 18-9
For a specific query, place the MERGE_AJ or HASH_AJ hints into the NOT IN subquery. MERGE_AJ uses a sort-merge anti-join and HASH_AJ uses a hash anti-join. For example:
SELECT * FROM emp
WHERE ename LIKE 'J%' AND
deptno IS NOT NULL AND
deptno NOT IN (SELECT /*+ HASH_AJ */ deptno FROM dept
WHERE deptno IS NOT NULL AND
loc = 'DALLAS');
If you wish the anti-join transformation always to occur if the conditions in the previous section are met, set the ALWAYS_ANTI_JOIN initialization parameter to MERGE or HASH. The transformation to the corresponding anti-join type then takes place whenever possible.
This guideline is based on these assumptions:
Indexes which are not used should be dropped. If all of the application SQL can be processed through EXPLAIN PLAN and the resulting plans are captured then any indexes which are not referenced in any execution plan can be detected. These indexes are typically, though not necessarily, non-selective.
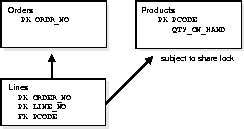
In many applications this foreign key index is never (or rarely) used to support a query. In the example shown there may be no normal requirement to locate all of the order lines for a given product. However when no index exists with LINES(PCODE) as its leading edge then a share lock will be placed on the Products table each time DML is performed against the Lines table. This in turn will only be a problem if the Products table itself is subject to frequent DML and in the example shown we might assume that the column QTY_ON_HAND is volatile, and that the table level share locks would cause severe contention problems.
If this contention starts to occur, then to remove it the application must either
A SQL statement can use an access path involving a composite index if the statement contains constructs that use a leading portion of the index. A leading portion of an index is a set of one or more columns that were specified first and consecutively in the list of columns in the CREATE INDEX statement that created the index. Consider this CREATE INDEX statement:
CREATE INDEX comp_ind
ON tab1(x, y, z);
To be sure that a SQL statement can use an access path that uses an index, be sure the statement contains a construct that makes such an access path available. If you are using the cost-based approach, you should also generate statistics for the index. Once you have made the access path available for the statement, the optimizer may or may not choose to use the access path, based on the availability of other access paths.
If you create new indexes to tune statements, you can also use the EXPLAIN PLAN command to determine whether the optimizer will choose to use these indexes when the application is run. If you create new indexes to tune a statement that is currently parsed, Oracle invalidates the statement. When the statement is next executed, the optimizer automatically chooses a new execution plan that could potentially use the new index. If you create new indexes on a remote database to tune a distributed statement, the optimizer considers these indexes when the statement is next parsed.
Also keep in mind that the means you use to tune one statement may affect the optimizer's choice of execution plans for others. For example, if you create an index to be used by one statement, the optimizer may choose to use that index for other statements in your application as well. For this reason, you should re-examine your application's performance and rerun the SQL trace facility after you have tuned those statements that you initially identified for tuning.
The parallel query option utilizes indexes effectively. It does not perform parallel index range scans, but it does perform parallel index lookups for parallel nested loop join execution. If an index is very selective (there are few rows per index entry), then it may be better to use sequential index lookup than parallel table scan.
SELECT COUNT(*) FROM t1, t2
WHERE t1.c1 > 50 and t1.c2 = t2.c1;
The plan is as follows:
SELECT STATEMENT
SORT AGGREGATE
HASH JOIN
TABLE ACCESS T1 FULL
INDEX T2_C1_IDX FAST FULL SCAN
Here, the fast full index scan can be used for table T2 since only column C1 is needed and there is no predicate that can be used as an index key. By contrast, FAST FULL SCAN could not be used for a nested loop join with the same join order: the join predicate can be used as an index key for that type of join.
FAST FULL SCAN has a special index hint, INDEX_FFS, which has the same format and arguments as the regular INDEX hint.
Consider, for example, a table named CUST with columns NAME, CUSTID, PHONE, ADDR, BALANCE, and an index named I_CUST_CUSTINFO on columns NAME, CUSTID and BALANCE of the table. To create a new index named I_CUST_CUSTNO on columns NAME and CUSTID, you would enter:
CREATE INDEX I_CUST_CUSTNO on CUST(NAME,CUSTID)
Oracle will automatically use the existing index (I_CUST_CUSTINFO) to create the new index rather than accessing the entire table. Note that the syntax used is the same as if the index I_CUST_CUSTINFO did not exist.
Similarly, if you have an index on the EMPNO and MGR columns of the EMP table, and you want to change the storage characteristics of that composite index, Oracle can use the existing index to create the new index.
Use the ALTER INDEX REBUILD command to reorganize or compact an existing index, or to change its storage characteristics. The REBUILD uses the existing index as the basis for the new index. All index storage commands are supported, such as STORAGE (for extent allocation), TABLESPACE (to move the index to a new tablespace), and INITRANS (to change the initial number of entries).
See Also: Oracle7 Server SQL Reference for more information about the CREATE INDEX and ALTER INDEX commands.
Bitmap indexes are not suitable for OLTP applications with large numbers of concurrent transactions modifying the data. These indexes are primarily intended for decision support in data warehousing applications where users typically query the data rather than update it.
Bitmap indexes are integrated with the Oracle cost-based optimization approach and execution engine. They can be used seamlessly in combination with other Oracle execution methods. For example, the optimizer can decide to perform a hash join between two tables using a bitmap index on one table and a regular B-tree index on the other. The optimizer considers bitmap indexes and other available access methods, such as regular B-tree indexes and full table scan, and chooses the most efficient method, taking parallelism into account where appropriate. Note also that parallel query works with bitmap indexes as with traditional indexes. Parallel create index and concatenated indexes are supported.
The purpose of an index is to provide pointers to the rows in a table that contain a given key value. For a regular index, this is achieved by storing a list of rowids for each key corresponding to the rows with that key value. (In ORACLE, each key value is stored repeatedly with each stored rowid.) With a bitmap index, a bitmap for each key value is used instead of a list of rowids. Each bit in the bitmap corresponds to a possible rowid, and if the bit is set, it means that the row with the corresponding rowid contains the key value. A mapping function is used to convert the bit position to an actual rowid, so the bitmap index provides the same functionality as a regular index even though it uses a different representation internally. If the number of different key values is small, bitmaps are very space efficient.
Bitmap indexing efficiently merges indexes corresponding to several conditions in the WHERE clause. Rows that satisfy some, but not all the conditions, are filtered out before the table itself is accessed. As a result, response time is improved, often dramatically.
For example, on a table with one million rows, a column with 10,000 distinct values is a candidate for a bitmap index. A bitmap index on this column can out-perform a B-tree index, particularly when this column is often queried in conjunction with other columns.
B-tree indexes are most effective for high-cardinality data: that is, data with many possible values, such as CUSTOMER_NAME or PHONE_NUMBER. A regular B-tree index can be several times larger than the indexed data. Used appropriately, bitmap indexes can be significantly smaller than a corresponding B-tree index.
In ad hoc queries and similar situations, bitmap indexes can dramatically improve query performance. AND and OR conditions in the WHERE clause of a query can be quickly resolved by performing the corresponding boolean operations directly on the bitmaps before converting the resulting bitmap to rowids. If the resulting number of rows is small, the query can be answered very quickly without resorting to a full table scan of the table.
Since MARITAL_STATUS, REGION, GENDER, and INCOME_LEVEL are all low-cardinality columns (there are only three possible values for marital status and region, two possible values for gender, and four for income level) it is appropriate to create bitmap indexes on these columns. A bitmap index should not be created on CUSTOMER# because this is a high-cardinality column. Instead, a unique B-tree index on this column in order would provide the most efficient representation and retrieval.
|
REGION='east'
|
REGION='central'
|
REGION='west'
|
|
1
|
0
|
0
|
|
0
|
1
|
0
|
|
0
|
0
|
1
|
|
0
|
0
|
1
|
|
0
|
1
|
0
|
|
0
|
1
|
0
|
Each entry (or "bit") in the bitmap corresponds to a single row of the CUSTOMER table. The value of each bit depends upon the values of the corresponding row in the table. For instance, the bitmap REGION='east' contains a one as its first bit: this is because the region is "east" in the first row of the CUSTOMER table. The bitmap REGION='east' has a zero for its other bits because none of the other rows of the table contain "east" as their value for REGION.
SELECT COUNT(*) FROM CUSTOMER WHERE MARITAL_STATUS = 'married' AND REGION IN ('central','west');
Executing a Query Using Bitmap Indexes
Bitmap indexes solve this dilemma. Because bitmap indexes can be efficiently combined during query execution, three small single-column bitmap indexes can do the job of six three-column B-tree indexes. Although the bitmap indexes may not be quite as efficient during execution as the appropriate concatenated B-tree indexes, the space savings more than justifies their use.
If a bitmap index is created on a unique key column, it will require more space than a regular B-tree index. However, for columns where each value is repeated hundreds or thousands of times, a bitmap index will typically be less than 25 percent of the size of a regular B-tree index. The bitmaps themselves are stored in compressed format.
Simply comparing the relative sizes of B-tree and bitmap indexes is not an accurate measure, however. Because of their different performance characteristics, you should keep B-tree indexes on high-cardinality data, while creating bitmap indexes on low-cardinality data.
A B-tree index entry contains a single rowid. Therefore, when the index entry is locked, a single row is locked. With bitmap indexes, an entry can potentially contain a range of rowids. When a bitmap index entry is locked, the entire range of rowids is locked. The number of rowids in this range affects concurrency. For example, a bitmap index on a column with unique values would lock one rowid per value: concurrency would be the same as for B-tree indexes. As rowids increase in a bitmap segment, concurrency decreases.
Locking issues affect data manipulation language operations, and thus may impact heavy OLTP environments. Locking issues do not, however, affect query performance. As with other types of indexes, updating bitmap indexes is a costly operation. Nonetheless, for bulk inserts and updates where many rows are inserted or many updates are made in a single statement, performance with bitmap indexes can be better than with regular B-tree indexes.
Although bitmap indexes are not appropriate for OLTP applications with a heavy load of concurrent insert, update, and delete operations, their effectiveness in a data warehousing environment is not diminished. In such environments, data is usually maintained via bulk inserts and updates. Index maintenance is deferred until the end of each DML operation. For example, if you insert 1000 rows, the inserted rows are all placed into a sort buffer and then the updates of all 1000 index entries are batched. Thus each bitmap segment is updated only once per DML operation, even if more than one row in that segment changes. This is why SORT_AREA_SIZE must be set properly for good performance with inserts and updates on bitmap indexes.
If numerous DML operations have caused increased index size and decreasing performance for queries, you can use the ALTER INDEX REBUILD command to compact the index and restore efficient performance.
CREATE BITMAP INDEX ...
All CREATE INDEX parameters except NOSORT are applicable to bitmap indexes. Multi-column (concatenated) bitmap indexes are supported; they can be defined over at most 14 columns. Other SQL statements concerning indexes, such as DROP, ANALYZE, ALTER, and so on, can refer to bitmap indexes without any extra keyword. The command ANALYZE INDEX VALIDATE STRUCTURE, however, is not applicable to bitmap indexes.
INDEX_COMBINE(table index1 index2 ...)
If no indexes are given as arguments for this hint, the optimizer will use on the table whatever boolean combination of bitmap indexes has the best cost estimate. If certain indexes are given as arguments, the optimizer will try to use some boolean combination of those particular bitmap indexes.
CREATE_BITMAP_AREA_SIZE: This parameter determines the amount of memory allocated for bitmap creation. The default value is 8 Mb. A larger value may lead to faster index creation. If cardinality is very small, you can set a small value for this parameter. For example, if cardinality is only 2 then the value can be on the order of kilobytes rather than megabytes. As a general rule, the higher the cardinality, the more memory is needed for optimal performance. This parameter is not dynamically alterable at the session level.
BITMAP_MERGE_AREA_SIZE: This parameter determines the amount of memory used to merge bitmaps retrieved from a range scan of the index. The default value is 1 Mb. A larger value should improve performance because the bitmap segments must be sorted before being merged into a single bitmap. This parameter is not dynamically alterable at the session level.
V733_PLANS_ENABLED determines whether bitmap access paths will be considered for regular indexes on the tables that have at least one bitmap index.
EXPLAIN PLAN FOR
SELECT * FROM T
WHERE
C1 = 2 AND C2 <> 6
OR
C3 BETWEEN 10 AND 20;
SELECT STATEMENT
TABLE ACCESS T BY ROWID
BITMAP CONVERSION TO ROWIDS
BITMAP OR
BITMAP MINUS
BITMAP MINUS
BITMAP INDEX C1_IND SINGLE VALUE
BITMAP INDEX C2_IND SINGLE VALUE
BITMAP INDEX C2_IND SINGLE VALUE
BITMAP MERGE
BITMAP INDEX C3_IND RANGE SCAN
Here, the following new row sources are used:
In order to use bitmap access paths for B-tree indexes, the rowids stored in the indexes must be converted to bitmaps. Once such a conversion has taken place, the various boolean operations available for bitmaps can be used. As an example, consider the following query, where there is a bitmap index on column C1, and regular B-tree indexes on columns C2 and C3.
EXPLAIN PLAN FOR
SELECT COUNT(*) FROM T
WHERE
C1 = 2 AND C2 = 6
OR
C3 BETWEEN 10 AND 20;
SELECT STATEMENT
SORT AGGREGATE
BITMAP CONVERSION COUNT
BITMAP OR
BITMAP AND
BITMAP INDEX C1_IND SINGLE VALUE
BITMAP CONVERSION FROM ROWIDS
INDEX C2_IND RANGE SCAN
BITMAP CONVERSION FROM ROWIDS
SORT ORDER BY
INDEX C3_IND RANGE SCAN
Here, a COUNT option for the BITMAP CONVERSION row source is used to count the number of rows matching the query. There are also conversions FROM ROWIDS in the plan in order to generate bitmaps from the rowids retrieved from the B-tree indexes. The occurrence of the ORDER BY SORT in the plan is due to the fact that the conditions on columns C3 result in more than one list of rowids being returned from the B-tree index. These lists are sorted before they can be converted into a bitmap.
For bitmap indexes with direct load, the UNRECOVERABLE and SORTED_INDEX flags are meaningless.
Performing an ALTER TABLE command that adds or modifies a bitmap-indexed column may cause indexes to be invalidated.
The command ANALYZE INDEX VALIDATE STRUCTURE is not applicable to bitmap indexes.
Bitmap indexes are not supported for Trusted Oracle.
Bitmap indexes are not considered by the rule-based optimizer.
Bitmap indexes cannot be used for referential integrity checking.
For normal indexes, a subquery can be used as an index driver if there is a predicate of the form col = (subquery). Such subqueries cannot be used as keys for a bitmap index.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |